
Integration solutions and technologies
Posted by Marcin Ziemek on 22-10-2022Would you like to learn about the most popular solutions and integration technologies? In this text you will learn what are REST resources, SOAP operations, message queues, message topics, flat files, database replication, ETL/ELT flows, integration bus and how to use them for IT system integration.
If you want to develop your knowledge of IT systems integration design, check out my book available at: https://integration.marcinziemek.com
Overview of integration solutions and technologies
Integration solutions and technologies must be chosen after determining the type of data processing (online, offline), integration mode (automatic, semi-automatic, manual), and type of integration (synchronous, asynchronous). One of the mistakes made when designing integration is choosing integration solutions and technologies before defining functional, non-functional, or business requirements.
The most popular integration solutions and technologies are:- REST resources,
- SOAP operations,
- Message queues (e.g. IBM MQ, RabbitMQ, Amazon SQS),
- Topics (e.g. Apache Kafka, Confluent Platform, Amazon SNS),
- Integration buses (e.g. webMethods, Mule),
- Flat files (e.g.CSV, TSV),
- Database replication,
- ETL/ELT flows (e.g. IBM DataStage, Hadoop with Spark).
When choosing a solution and integration technology, attention should be paid to the team's competences, costs, or migration to another solution. There may be more criteria that we must consider. When we decide to choose message queues and we have competence in working with IBM MQ in the team, then this should be considered when choosing a solution.
In the following, we will briefly discuss various integration solutions and technologies.
REST resources
REST (Representational State Transfer) is an architectural style that operates on resources. Resources have URIs, they can have many representations, operations carried out on them, such as getting, creating, modifying, or deleting. They are implemented using HTTP methods. Because REST is stateless, the request must contain all the necessary data to handle the event. It was introduced in 2000 by Roy T. Fielding.
In REST we use HTTP methods such as GET, HEAD, PUT, POST or DELETE.
The GET and HEAD methods are secure and can be cached.
The PUT method is used to create or modify a resource, similarly to the POST method. The DELETE method is used to delete a resource.
When designing RESTful services, consider the following:- specify the resource URI (select the noun that will represent the resource),
- specifying the methods supported by the resource (selection of HTTP methods),
- specify supported resource formats (JSON, XML, etc.).
SOAP operations
SOAP (Simple Object Access Protocol) is a communication protocol that uses XML and most often the HTTP protocol to move data. Other protocols, such as SMTP or UDP, can also be used for data transmission. SOAP can only communicate using XML. Ensures data integrity and confidentiality using the WS-Security extension. SOAP enables stateless and session-free operation. Provides services defined according to the WSDL standard.
A SOAP document consists of the following elements:- The Envelope parent,
- Header, which allows you to pass specific message information (for example, authentication) to the application,
- the Body element storing the request and response,
- a Fault element containing error and status information.
The technology used to build distributed web services is Web Services. The services implement business logic and are available via the SOAP protocol.
Web Services architecture consists of:- Web Services client – an application that wants to call the service,
- Web Services component – a remote component implementing business logic,
- Application Server.
Web Services components can be stateful or stateless.
Message queues
Message queues are a method that allows the producer and the consumer to work together in an asynchronous manner. The message is queued by the manufacturer. The consumer then has the option to download the message. The use of message queues does not require real-time availability of the producer and consumer. Message queues can also be used to increase the reliability of the solution. Communications are downloaded by the consumer at the time when he can process the request. Messages may be held in line to wait for consumer availability.
Queue-defining properties include:- Persistence – determines whether messages will be stored in memory or saved on disk or in the database,
- Security – determines the permissions to the queue,
- Maximum message size,
- Delete messages – defines the rules for removing messages from the queue,
- Rules for the delivery of messages,
- Message routing rules.
Message queues enable the integration of different systems, provide a loose connection and support data exchange in a simple, secure, and secure way.
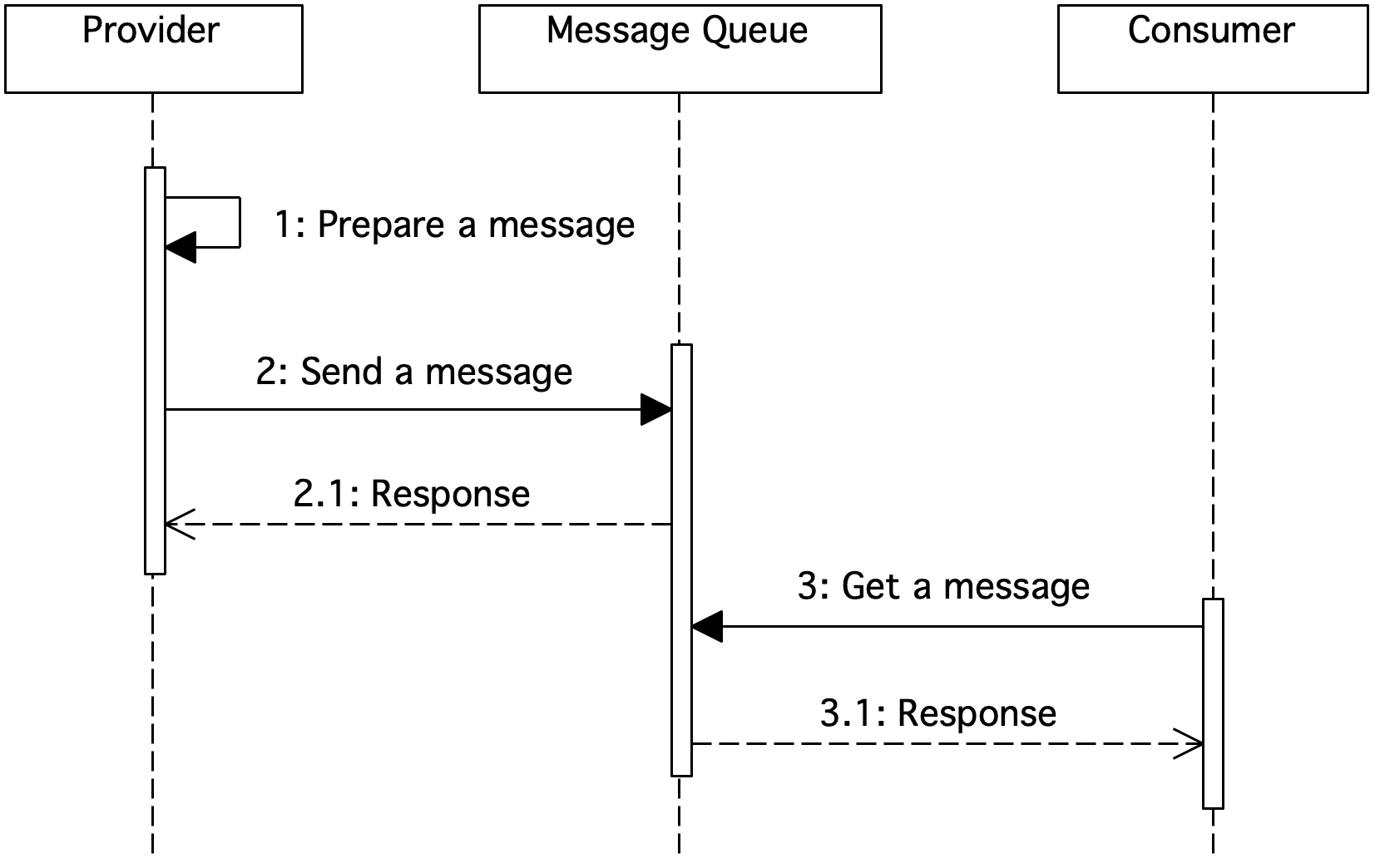
Figure 1. Sequence diagram showing message queue usage

Figure 2. Component diagram showing the usage of the message queue
The vendor passes the message to the queue. The consumer then downloads a message from it. Communication can be two-way. The consumer may relay a message through a queue to a supplier through the same queue or another.
By using the queue, the consumer does not have to be available at the time of transmission of the message by the supplier. When the consumer is available, he can download the message. Both suppliers and consumers can be many. Through queues we can forward any type of message (text, XML, video). Queues are used to hold messages. Messages can be persistent or impermanent. Queues are managed by a queue manager.
Popular implementations of message queues are Amazon SQS (https://aws.amazon.com/sqs/), IBM MQ (https://www.ibm.com/pl-pl/products/mq) or RabbitMQ (https://www.rabbitmq.com/).
Message topics
Message topics are a method of sending messages between applications. Messages are grouped into topics. The topic can have many manufacturers and many consumers news. The manufacturer or manufacturers convey messages on a certain topic. The messages are then retrieved by the consumer or consumers. This approach uses the terminology of publishing and subscribing to messages.
Producers publish news on specific topics. Consumers subscribe to the topics from which they receive news. This is a publishing and subscription pattern.
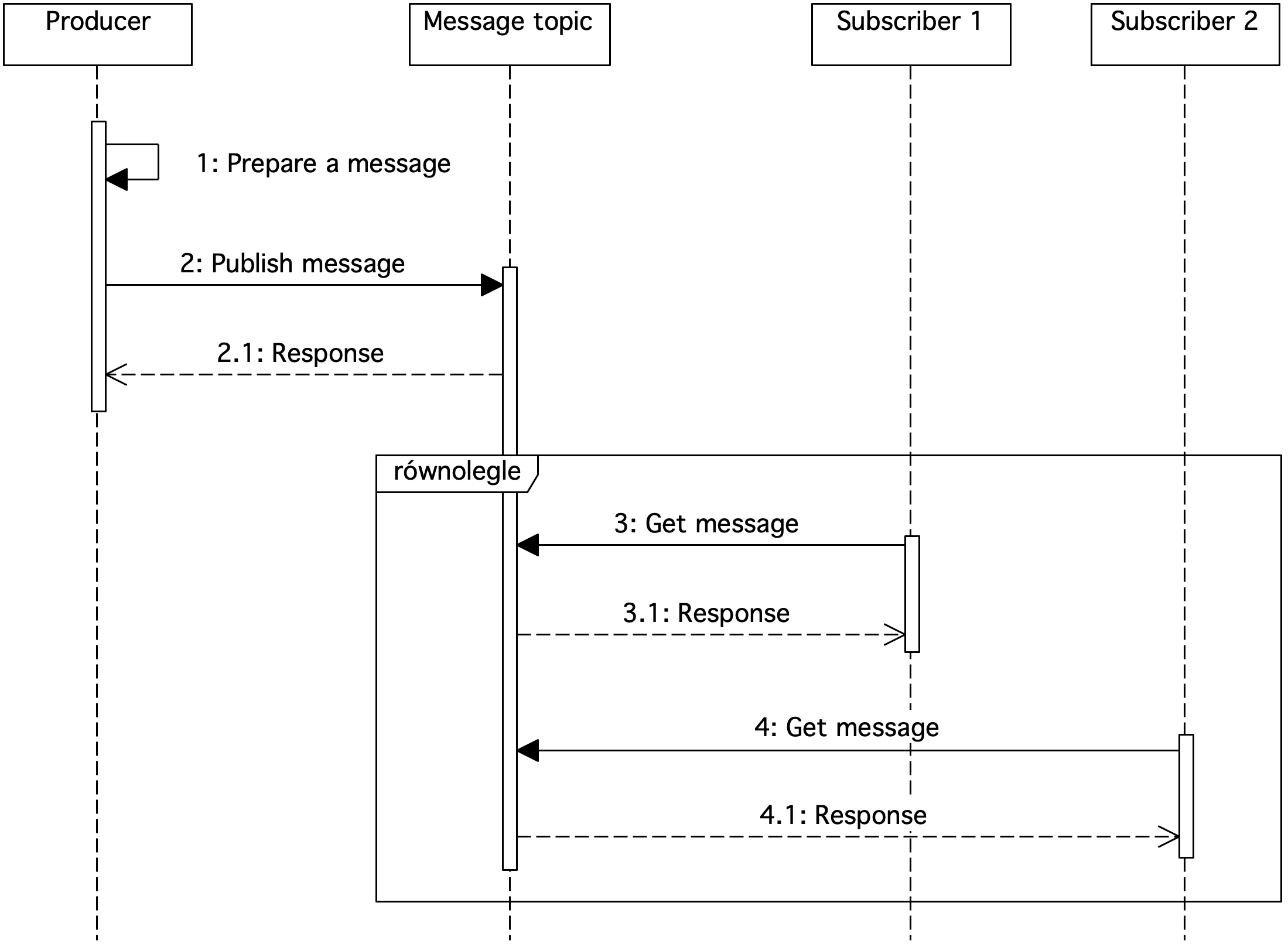
Figure 3. Sequence diagram showing the usage of message subjects

Figure 4. Component diagram showing the use of message subjects
In the publish-subscribe method, messages are stored in subjects. News is published by producers, forwarded to the topic from which the news is consumed by subscribers. In this method, there can be multiple recipients of the same message.
Popular implementations of news subjects include Apache Kafka (https://kafka.apache.org/), Confluent Platform (https://www.confluent.io/), and Amazon SNS (https://aws.amazon.com/sns/).
Flat files
Application integration can also be achieved through flat CSV (Comma Separated Values) or TSV (Tab Separated Values) files. In CSV files, the separator is a comma. In the case of TSV, this is a tab.
The provider generates a flat file, which is then forwarded to the consumer.
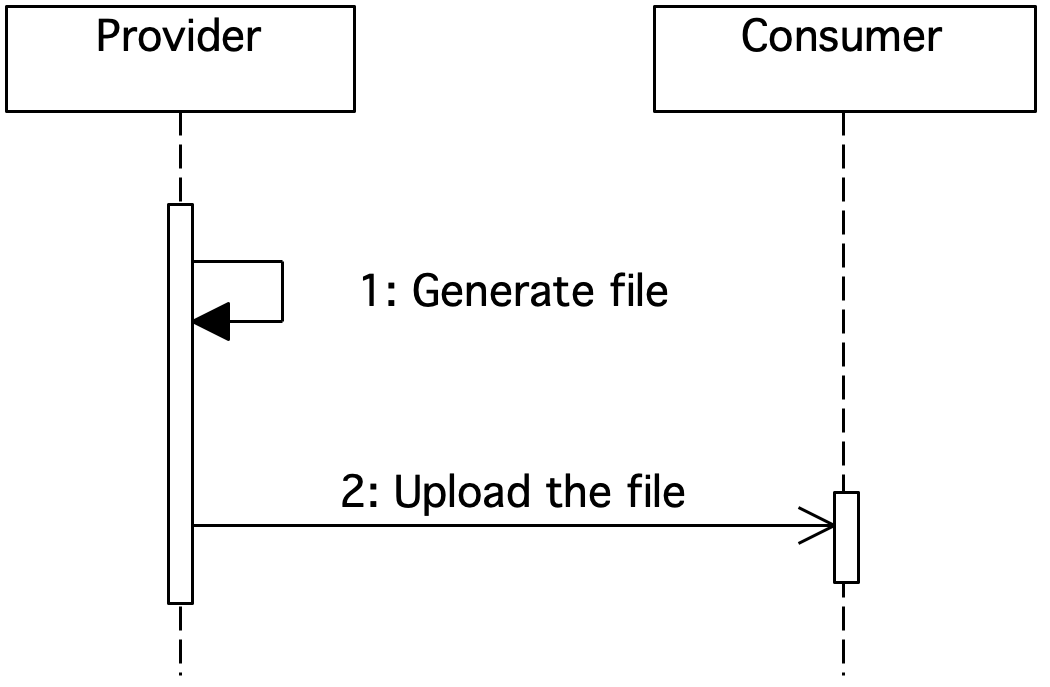
Figure 5. Sequence diagram showing file-based integration
Flat file integration is very often used when data can be uploaded, for example, once a day or monthly. It also enables the transfer of very large data sets.
Database replication
Database replication is the act of copying data from the source database to the destination database. The entire database or selected tables can be replicated. The copied data is available to the consumer in the target database. We use replication to shorten data access time, increase reliability and performance of the solution.
We meet different types of replications:- snapshot,
- transactional,
- merge.
- central publisher – data is replicated from one database to many others,
- central subscriber – data is replicated from many publishers to one subscriber,
- equivalent – there are any number of publishers and subscribers.
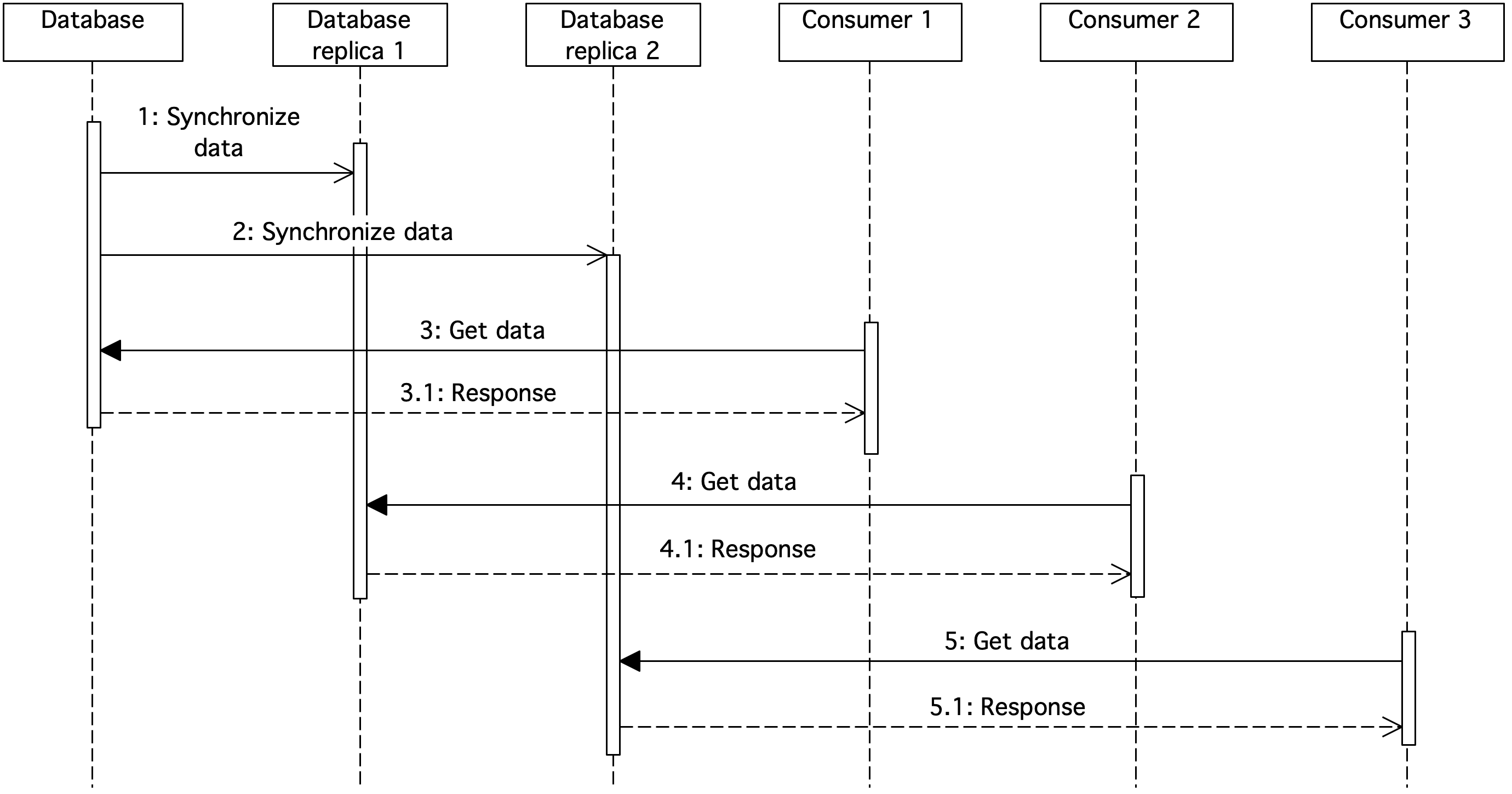
Figure 6. Sequence diagram showing database replication
The diagram shows the replication of data from one database to two others. Consumer 1 retrieves the data from the database. Consumer 2 and 3 download data from the Replica 1 and Replica 2 databases, respectively.
ETL flows
ETL (Extract, Transform, Load) – this is a process that involves downloading, transforming, and loading data. It can be used to transfer data between IT systems. In the first step, data is downloaded from the source system or systems. This is the stage of data extraction. The downloaded data is then transformed. It may consist of cleaning, filtering, or transforming data. In the next step, the data is loaded into the target system or systems.
In ETL flows, all stages, i.e., downloading, transforming, and loading data, are carried out outside the source and target system. We use an additional tool.
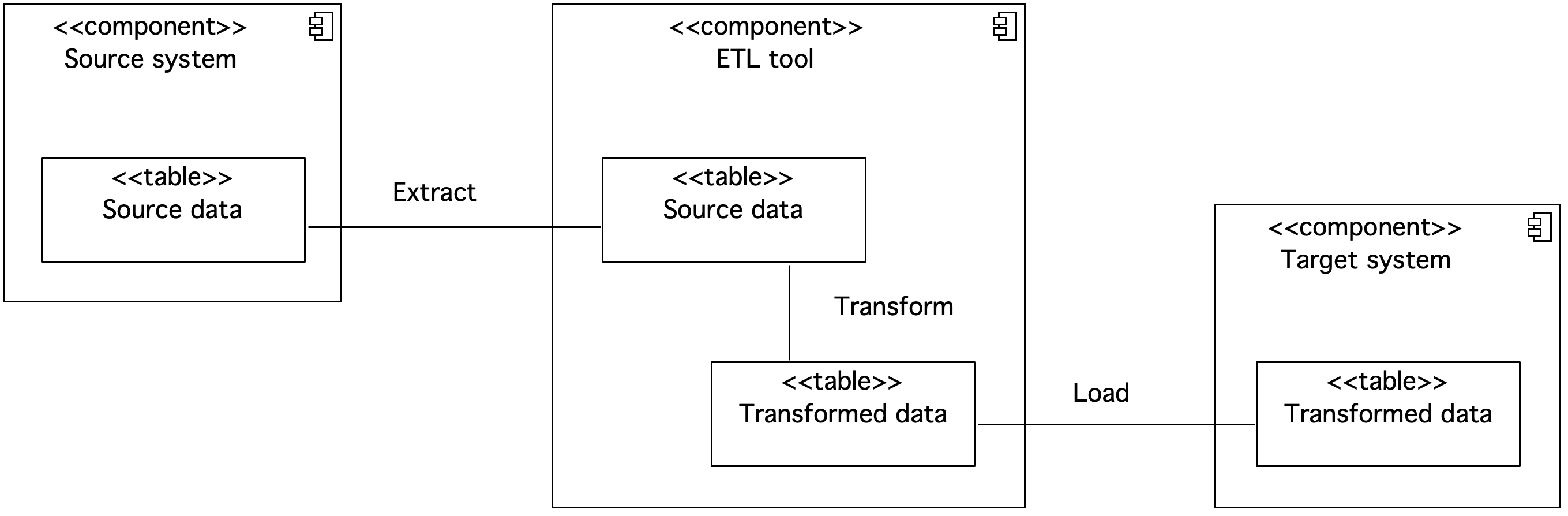
Figure 7. Component diagram showing the ETL tool
In the diagram, the transmitted data is presented as a component with a table stereotype. The ETL tool retrieves data from the source system. The source data is then transformed. The transformed data is loaded into the target system by the ETL tool. In the ETL flow, the steps of downloading, transforming, and loading are carried out through a tool external to the source system and the target system.
Popular tools used to implement ETL/ELT are IBM DataStage (https://www.ibm.com/products/datastage), Apache NiFi (https://nifi.apache.org/), Apache Spark (https://spark.apache.org/) with Hadoop (https://hadoop.apache.org/) or Amazon Glue (https://aws.amazon.com/glue/).
ELT flows
ELT (Extract, Load, Transform) – this is a process that involves downloading, loading, and transforming data. The steps for loading and transforming data are in a different order compared to the ETL process. In the first step, data is downloaded from the source system or systems and then loaded into the target system. The next stage is the transformation of the data, which can be carried out by the source system.
Very often, the transformation in ELT processes is carried out by the database engine of the target system, therefore we do not have to use an additional tool.
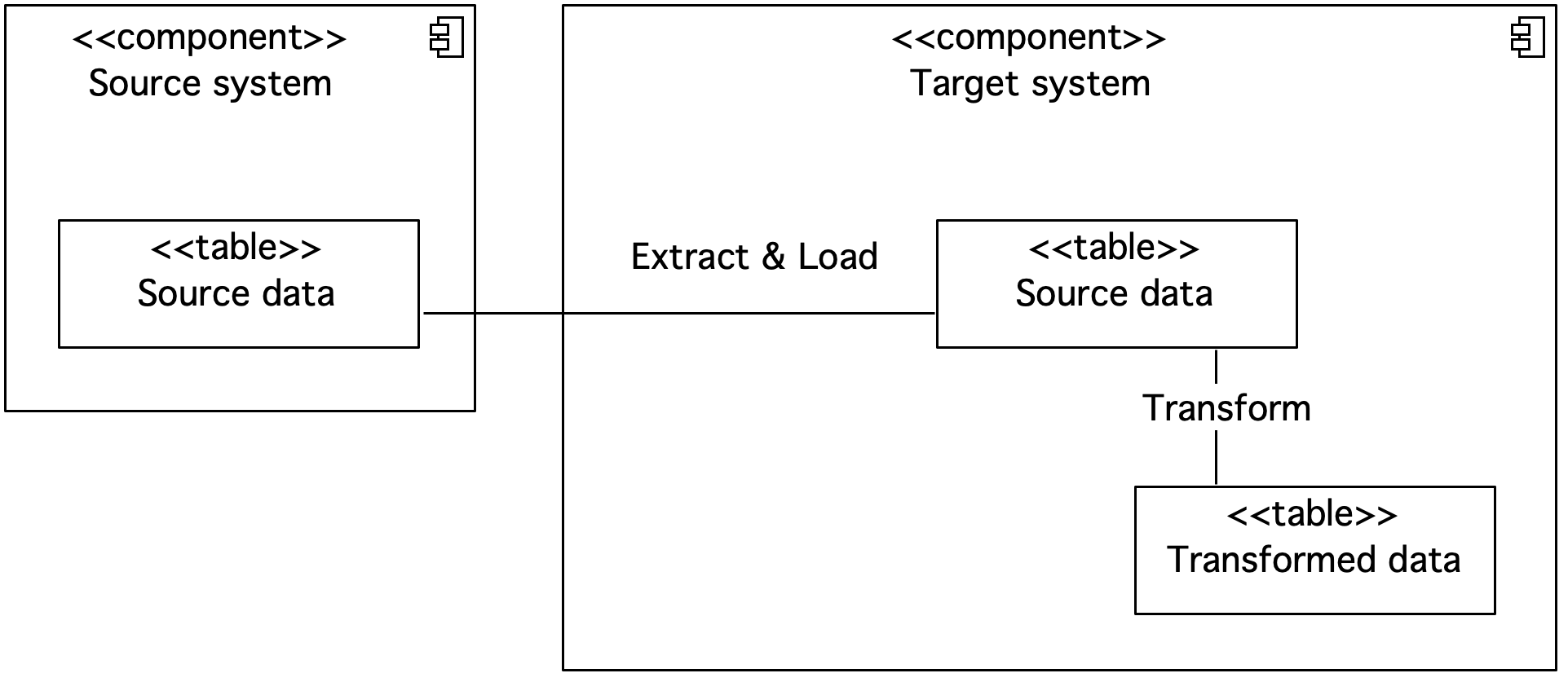
Figure 8. Component diagram showing the ELT
In the diagram, the transmitted data is presented as a component with a table stereotype. The source data is extracted and loaded into the target system. The data transformation is then performed. In the ELT flow, the steps of extraction, loading and transformation can be carried out by the target system.
Popular tools used to implement ETL/ELT are IBM DataStage, Apache NiFi, Apache Spark with Hadoop, or Amazon Glue.
Integration Bus
The Enterprise Service Bus enables the integration of heterogeneous IT systems using a central integration bus. ESB provides easy connection or disconnection of the IT system via channels and adapters. It provides services that can be used by different consumers. The use of a canonical data model improves the management of the message model. The integration bus eliminates the problem of point-to-point integration between IT systems. It can be a bottleneck.
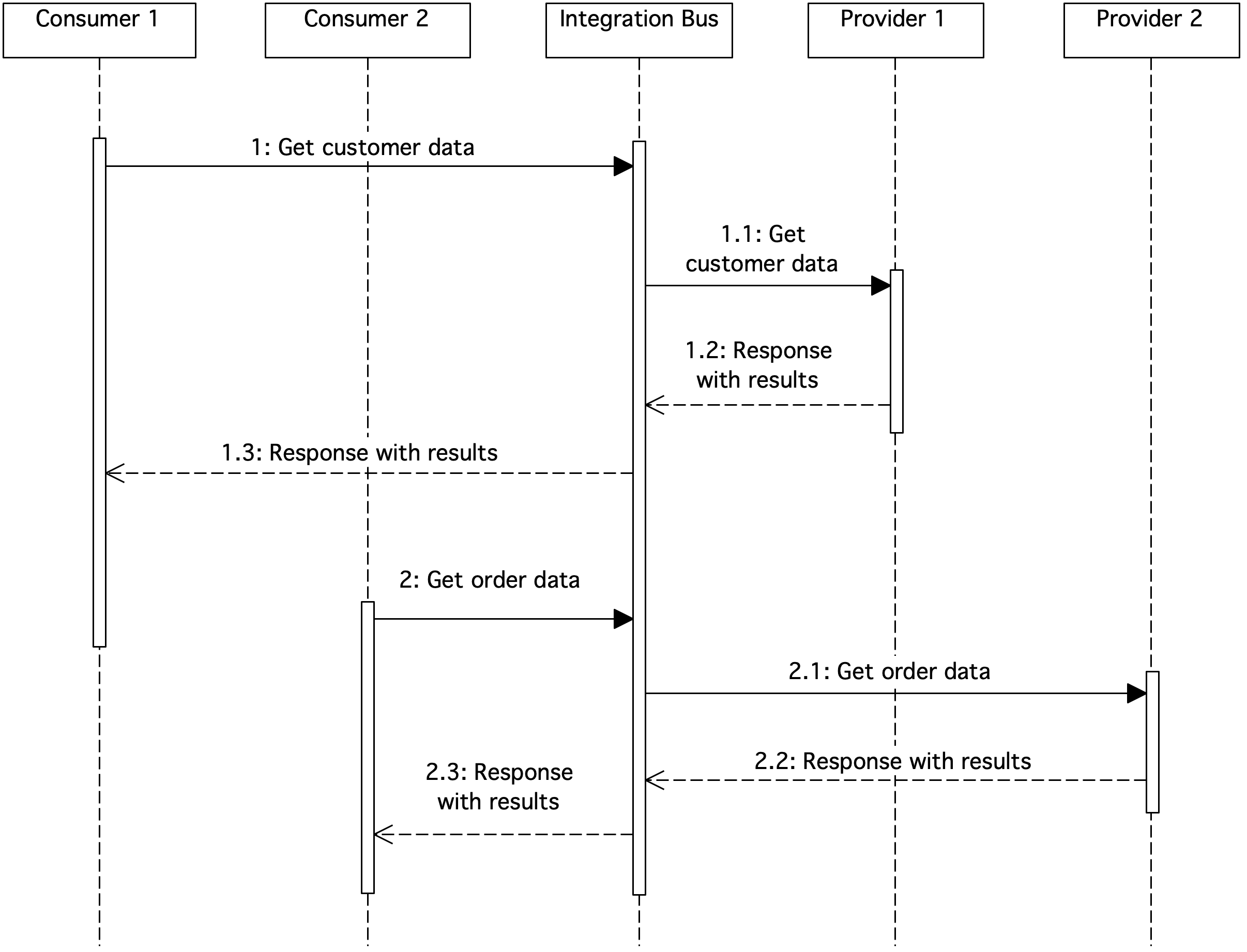
Figure 9. Sequence diagram showing the integration bus
The ESB integration bus makes services available to consumers. In this case, services are available to download customer data and download order data. Consumers do not need to know the details of the operation of the services or IT systems from which the data is downloaded.
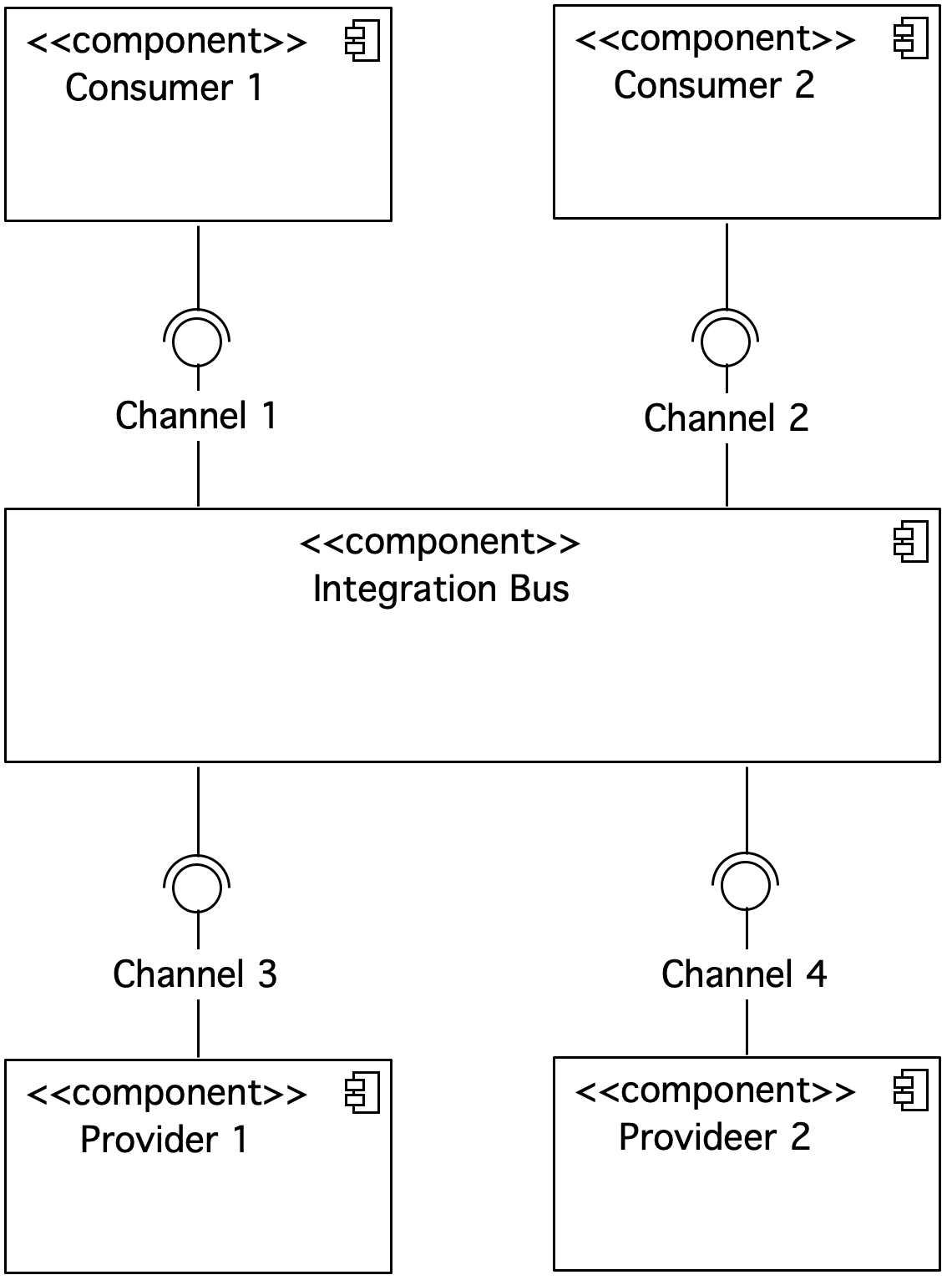
Figure 10. Component diagram showing the integration bus
The ESB integration bus also covers the service logic. The consumer does not have to implement complex website logic. The service made available on ESB can be used by other consumers. The use of a canonical data model allows you to easily connect and disconnect IT systems.
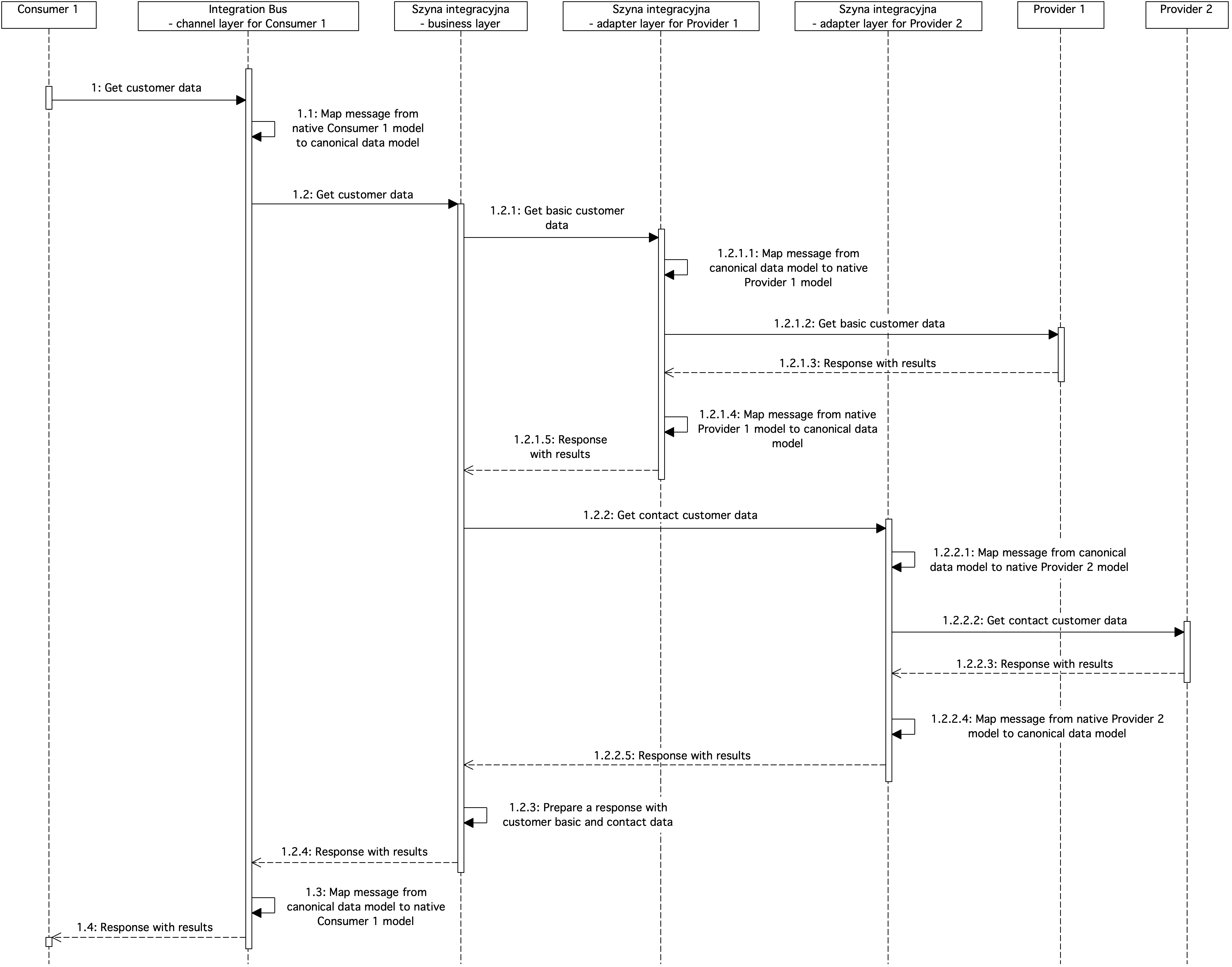
Figure 11. Sequence diagram showing integration bus service details
The diagram shows an example of a flow on an ESB integration bus. The consumer submits a request to download customer data in accordance with its native data model. The consumer integrates with the channel layer of the integration bus, where the message is transformed from the native Consumer 1 format to the canonical data model. Then the message is forwarded to the business layer of customer data retrieval.
Services at the business tier use a canonical data model. This allows you to easily integrate business-tier services with each other. The business service contains logic to retrieve the customer's master data from the Supplier 1 system and the customer's contact information from the Supplier 2 system. To do this, the business service forwards the request to retrieve the customer's master data to the adapter layer of Provider 1's system. In the adapter layer of Provider 1, the message is converted from the canonical model to the native model of Provider 1. The adapter layer then sends a request to Provider 1. When a response is received in the adapter layer of Provider 1, the message is converted from the native form of Provider 1 to the canonical data model and forwarded to the business layer.
In the next step in the business layer, the customer's contact details are downloaded. For this purpose, the request is forwarded to the adapter layer of the Supplier 2 system. In the adapter layer, the message is transformed from canonical to native form for the Provider 2 system and the Provider 2 system is called. After receiving the results in the adapter layer, the message is converted from the native form of Provider 2 to the canonical form and the results are transferred to the business layer.
The next step is to combine the customer data downloaded from the Supplier 1 system and the customer's contact data downloaded from the Supplier 2 system. After preparing the answer, it is forwarded to the channel layer of Consumer 1, where the message is mapped from canonical to native Consumer 1 and the results are returned to Consumer 1.
Common ESB implementations are webMethods Integration Server (https://www.softwareag.com/en_corporate/platform/integration-apis/webmethods-integration.html) (webMethods ESB), or Mule ESB.
Thank you for reading the article. If you would like to share your comment with me, write to me at marcin@marcinziemek.com
If you want to develop your knowledge of IT systems integration design, check out my book available at: https://integration.marcinziemek.com