
Rozwiązania oraz technologie integracyjne
Opublikował Marcin Ziemek w dniu 22-10-2022Czy chciałbyś poznać najpopularniejsze rozwiązania oraz technologie integracyjne? Z tego tekstu dowiesz się czym są zasoby REST, operacje SOAP, kolejki komunikatów, tematy wiadomości, pliki płaskie, replikacja bazy danych, przepływy ETL/ELT, szyna integracyjna oraz jak je wykorzystać do integracji systemów IT.
Jeśli chcesz rozwinąć swoją wiedzę z zakresu projektowania integracji systemów IT, sprawdź moją książkę dostępną pod adresem: https://integracja.marcinziemek.com
Przegląd rozwiązań oraz technologii integracji
Rozwiązania oraz technologie integracyjne muszą zostać wybrane po ustaleniu typu przetwarzania danych (online, offline), trybu integracji (automatyczna, semi-automatyczna, manualna) oraz typu integracji (synchroniczna, asynchroniczna). Jednym z błędów popełnianych podczas projektowania integracji jest wybór rozwiązania i technologii integracyjnej przed ustaleniem wymagań funkcjonalnych, niefunkcjonalnych czy procesów biznesowych.
Najpopularniejszymi rozwiązaniami i technologiami integracyjnymi są:- Zasoby REST,
- Operacje SOAP,
- Kolejki komunikatów (np. IBM MQ, RabbitMQ, Amazon SQS),
- Tematy wiadomości (np. Apache Kafka, Confluent Platform, Amazon SNS),
- Szyny integracyjne (np. webMethods, Mule),
- Pliki płaskie (np. CSV, TSV),
- Replikacja bazy danych,
- Przepływy ETL/ELT (np. IBM DataStage, Hadoop ze Spark).
Przy wyborze rozwiązania oraz technologii integracyjnej należy zwrócić uwagę na kompetencje zespołu, koszty czy migrację do innego rozwiązania. Kryteriów, które musimy wziąć pod uwagę może być więcej. Gdy zdecydujemy się na wybór kolejek komunikatów oraz posiadamy w zespole kompetencje w pracy z IBM MQ, wówczas należy uwzględnić to podczas wyboru rozwiązania.
W dalszej części omówimy pokrótce różne rozwiązania oraz technologie integracyjne.
Zasoby REST
REST (ang. Representational State Transfer) jest stylem architektonicznym operującym na zasobach. Zasoby posiadają identyfikatory URI, mogą mieć wiele reprezentacji, operacji na nich przeprowadzanych, jak pobranie, utworzenie, modyfikacja czy usunięcie. Realizowane są za pomocą metod HTTP. REST jest bezstanowy, dlatego żądanie musi zawierać wszystkie niezbędne dane w celu obsługi zdarzenia. Został wprowadzony w 2000 roku przez Roya T. Fieldinga.
W REST wykorzystujemy metody HTTP takie jak GET, HEAD, PUT, POST czy DELETE.
Metody GET oraz HEAD są bezpieczne i mogą być buforowane.
Metoda PUT służy do tworzenia lub modyfikacji zasobu, podobnie metoda POST. Metoda DELETE jest wykorzystywana do usuwania zasobu.
Podczas projektowania usług typu RESTful warto kierować się następującymi zasadami:- określenie identyfikatora URI zasobu (wybór rzeczownika, który będzie reprezentował zasób),
- określenie metod obsługiwanych przez zasób (wybór metod HTTP),
- określenie obsługiwanych formatów zasobu (JSON, XML itp.).
Operacje SOAP
SOAP (ang. Simple Object Access Protocol) jest protokołem komunikacyjnym wykorzystującym XML oraz najczęściej protokół HTTP w celu przenoszenia danych. Do transmisji danych można wykorzystać również inne protokoły, takie jak SMTP czy UDP. Protokół SOAP umożliwia komunikację tylko z użyciem języka XML. Zapewnia integralność oraz poufność danych poprzez wykorzystanie rozszerzenia WS-Security. SOAP umożliwia pracę bezstanową oraz z wykorzystaniem sesji. Udostępnia usługi zdefiniowane zgodnie ze standardem WSDL.
Dokument SOAP zbudowany jest z następujących elementów:- elementu nadrzędnego Envelope,
- elementu Header, który umożliwia przekazanie do aplikacji specyficznych informacji o komunikacie (na przykład związanych z uwierzytelnianiem),
- elementu Body przechowującym żądanie oraz odpowiedź,
- elementu Fault zawierającym informację o błędzie oraz statusie.
Technologią wykorzystywaną do budowy rozproszonych usług sieciowych jest Web Services. Usługi realizują logikę biznesową oraz dostępne są za pośrednictwem protokołu SOAP.
Architektura Web Services składa się z:- klienta Web Services – aplikacji, która chce wywołać usługę,
- komponentu Web Services – komponentu zdalnego implementującego logikę biznesową,
- serwera aplikacji.
Komponenty Web Services mogą być stanowe bądź bezstanowe.
Kolejki komunikatów
Kolejki komunikatów są metodą umożliwiającą współpracę producenta oraz konsumenta w sposób asynchroniczny. Wiadomość umieszczana jest w kolejce przez producenta. Następnie konsument ma możliwość pobrania wiadomości. Wykorzystanie kolejek komunikatów nie wymaga dostępności producenta oraz konsumenta w czasie rzeczywistym. Kolejki komunikatów mogą być wykorzystane również w celu zwiększenia niezawodności rozwiązania. Komunikaty pobrane są przez konsumenta w chwili, gdy jest w stanie przetworzyć żądanie. Wiadomości mogą być przetrzymywane w kolejce w celu oczekiwania dostępności konsumenta.
Właściwościami definiującymi kolejkę są między innymi:- Trwałość – określa, czy wiadomości będą przechowywane w pamięci, czy zapisywane na dysku bądź w bazie,
- Bezpieczeństwo – określa uprawnienia do kolejki,
- Maksymalny rozmiar wiadomości,
- Usuwanie wiadomości – określa reguły usuwania wiadomości z kolejki,
- Reguły doręczenia wiadomości,
- Reguły routowania wiadomości.
Kolejki komunikatów umożliwiają integrację różnych systemów, zapewniają luźne powiązanie oraz wspierają wymianę danych w prosty, pewny oraz bezpieczny sposób.
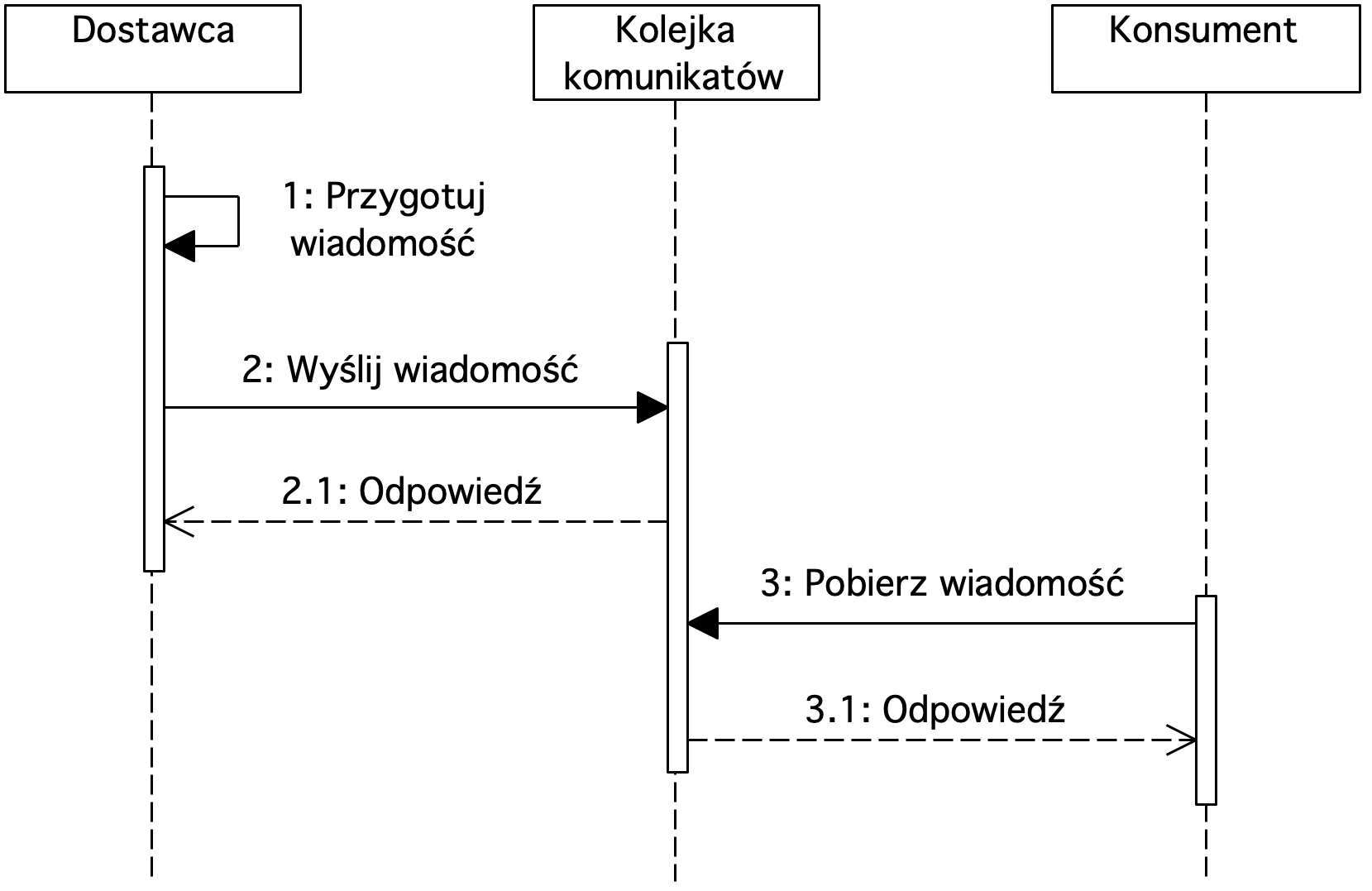
Rysunek 1. Diagram sekwencji prezentujący wykorzystanie kolejki komunikatów

Rysunek 2. Diagram komponentów prezentujący wykorzystanie kolejki komunikatów
Dostawca przekazuje wiadomość do kolejki. Następnie konsument pobiera z niej wiadomość. Komunikacja może być dwukierunkowa. Konsument może przekazać wiadomość poprzez kolejkę do dostawcy za pośrednictwem tej samej kolejki lub innej.
Poprzez wykorzystanie kolejki konsument nie musi być dostępny w chwili przekazania wiadomości przez dostawcę. Gdy konsument będzie dostępny, wówczas ma możliwość pobrania wiadomości. Zarówno dostawców jak i konsumentów może być wielu. Za pośrednictwem kolejek możemy przekazać dowolnego typu wiadomości (tekstowe, XML, video). Kolejki wykorzystywane są do przetrzymywania wiadomości. Wiadomości mogą być trwałe lub nietrwałe. Kolejki zarządzane są przez managera kolejek.
Popularnymi implementacjami kolejek komunikatów są Amazon SQS (https://aws.amazon.com/sqs/) , IBM MQ (https://www.ibm.com/pl-pl/products/mq) czy RabbitMQ (https://www.rabbitmq.com/).
Tematy wiadomości
Tematy wiadomości są metodą przesyłania komunikatów (ang. messages) pomiędzy aplikacjami. Wiadomości grupowane są w tematy (ang. topics). Temat może posiadać wielu producentów oraz wielu konsumentów wiadomości. Producent lub producenci przekazują wiadomości na pewien temat. Następnie wiadomości są pobierane przez konsumenta bądź konsumentów. W tym podejściu używa się terminologii publikowania oraz subskrypcji wiadomości.
Producenci publikują wiadomości na określone tematy. Konsumenci subskrybują się na tematy, z których otrzymują wiadomości. Jest to wzorzec publikowania oraz subskrypcji.
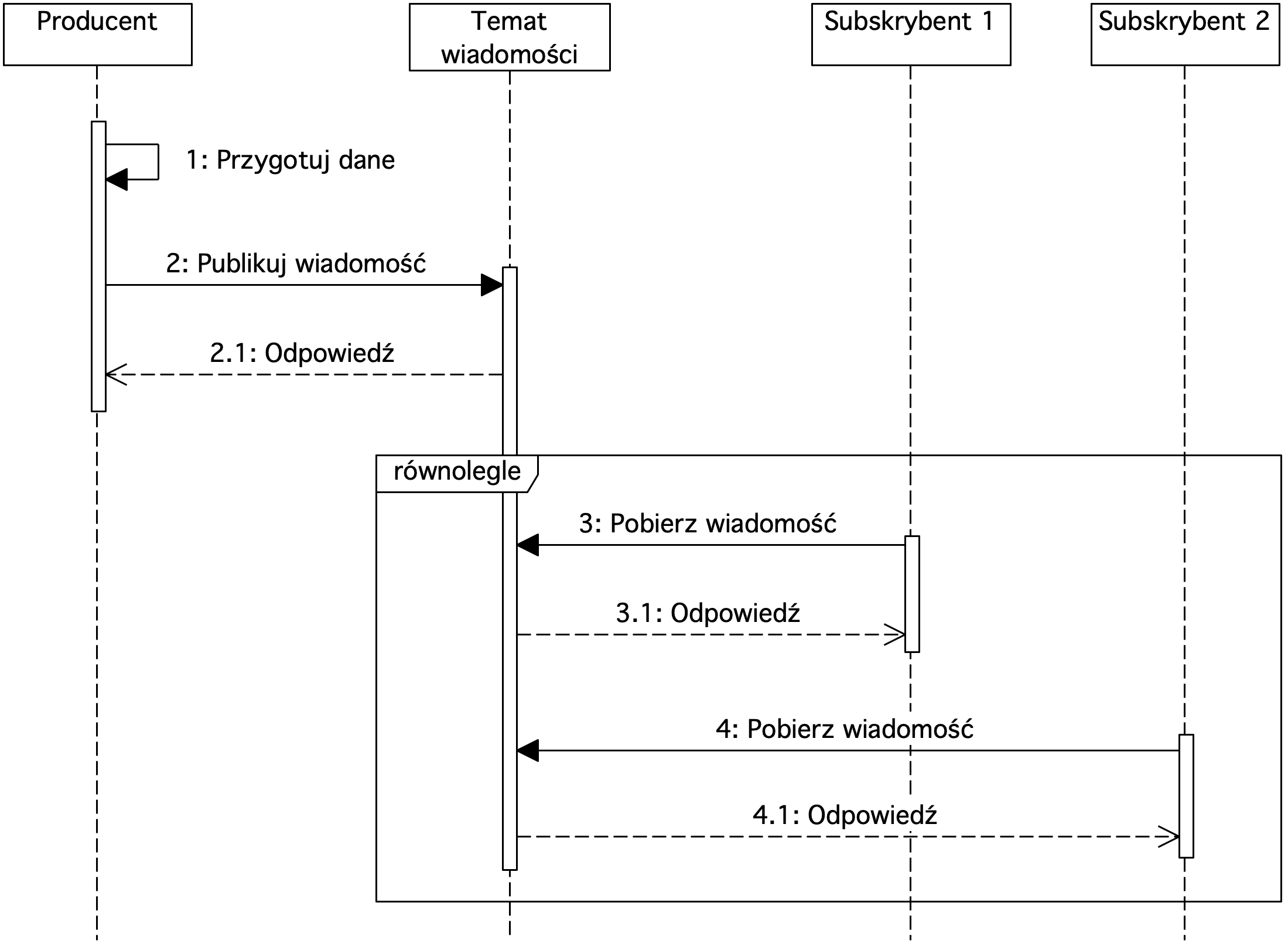
Rysunek 3. Diagram sekwencji prezentujący wykorzystanie tematów wiadomości
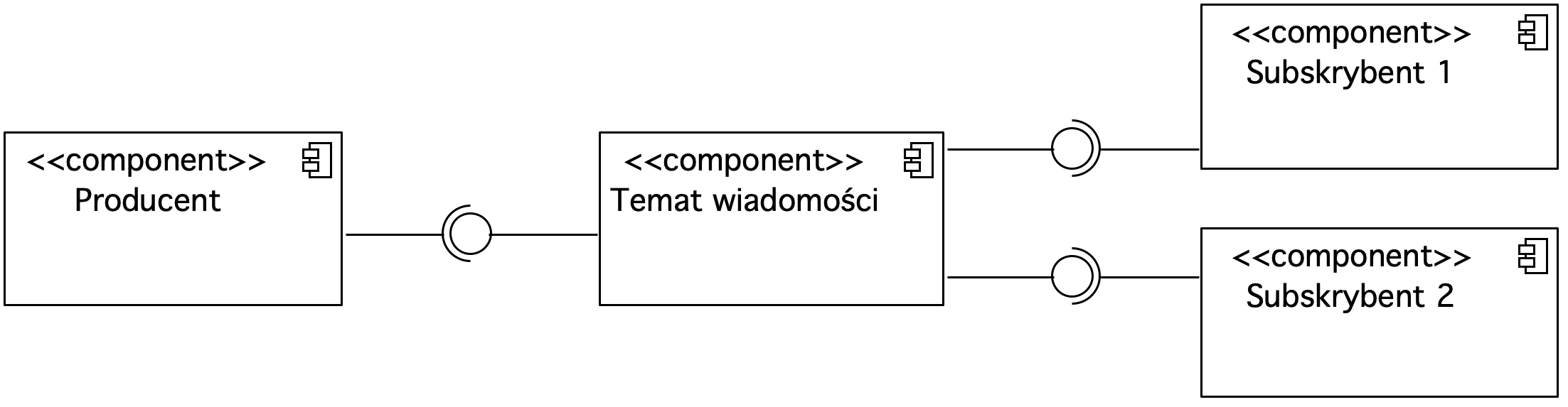
Rysunek 4. Diagram komponentów prezentujący wykorzystanie tematów wiadomości
W metodzie publikuj-subskrybuj wiadomości przechowywane są w tematach. Wiadomości publikowane są przez producentów, przekazywane do tematu, z którego wiadomości są konsumowane przez subskrybentów. W tej metodzie może być wielu odbiorców tej samej wiadomości.
Popularnymi implementacjami tematów wiadomości są Apache Kafka (https://kafka.apache.org/), Confluent Platform (https://www.confluent.io/) czy Amazon SNS (https://aws.amazon.com/sns/).
Pliki płaskie
Integracja aplikacji może zostać zrealizowana również poprzez pliki płaskie CSV (ang. Comma Separated Values) bądź TSV (ang. Tab Separated Values). W plikach CSV separatorem jest znak przecinka. W przypadku TSV jest to tabulator.
Producent generuje plik płaski, który następnie przekazywany jest do konsumenta.
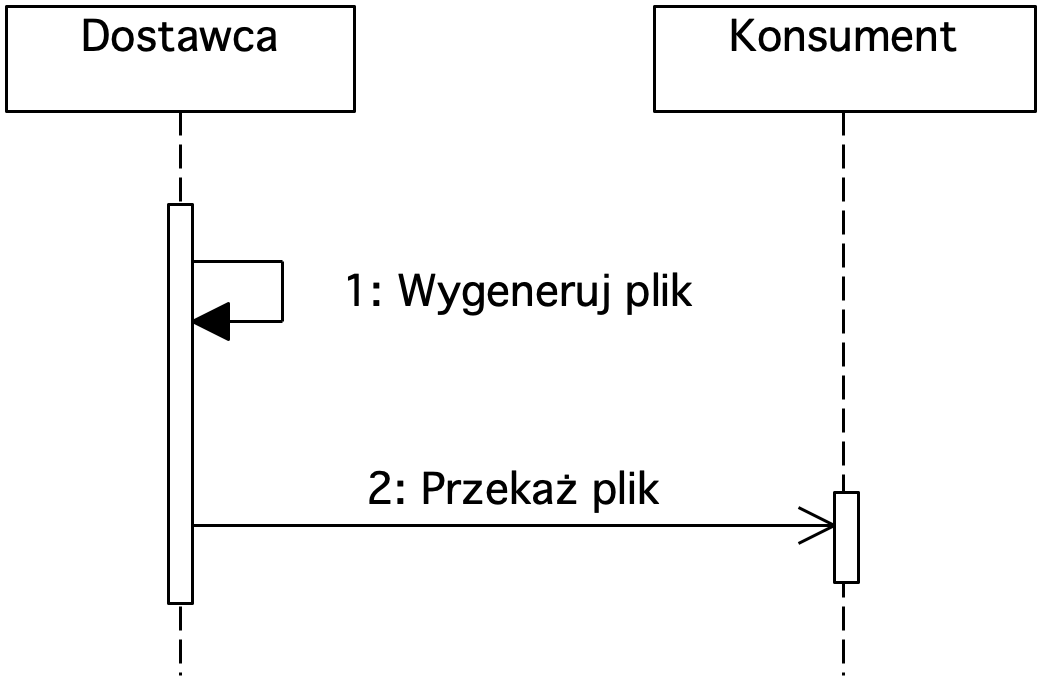
Rysunek 5. Diagram sekwencji prezentujący integrację za pośrednictwem plików
Integracja oparta na plikach płaskich jest bardzo często wykorzystywana, gdy dane mogą zostać przekazane na przykład raz dziennie czy miesięcznie. Umożliwia również przekazanie bardzo dużych zbiorów danych.
Replikacja bazy danych
Replikacja bazy danych polega na skopiowaniu danych ze źródłowej do docelowej bazy danych. Replikowana może być cała baza czy wybrane tabele. Skopiowane dane dostępne są dla konsumenta w bazie docelowej. Replikację stosujemy w celu skrócenia czasu dostępu do danych, zwiększenia niezawodności oraz wydajności rozwiązania.
Spotykamy różne typy replikacji:- migawkowa (ang. snapshot),
- transakcyjna (ang. transactional),
- łączeniowa (ang. merge).
- centralnego wydawcy – dane replikowane są z jednej bazy do wielu innych,
- centralnego subskrybenta – dane replikowane są z wielu wydawców do jednego subskrybenta,
- równorzędny – występuje dowolna liczba wydawców oraz subskrybentów.
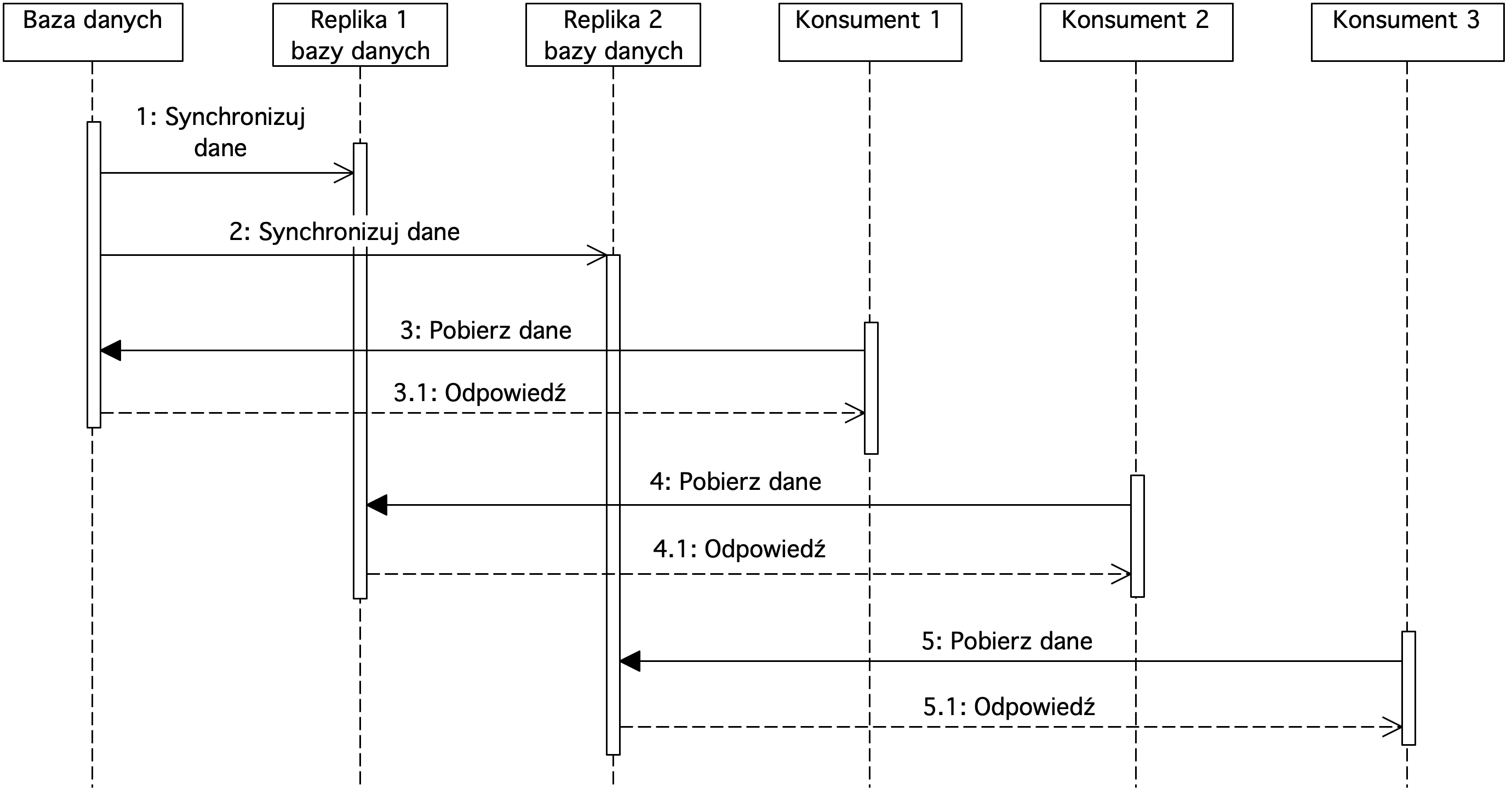
Rysunek 6. Diagram sekwencji prezentujący replikację bazy danych
Na diagramie przedstawiona została replikacja danych z jednej bazy do dwóch innych. Konsument 1 pobiera dane z bazy danych. Konsument 2 oraz 3 pobierają dane odpowiednio z bazy Replika 1 oraz Replika 2.
Przepływy ETL
ETL (ang. Extract, Transform, Load) – jest to proces, który polega na pobraniu, przekształceniu oraz załadowaniu danych. Może zostać wykorzystany w celu przekazania danych pomiędzy systemami informatycznymi. W pierwszym kroku następuje pobranie danych z systemu źródłowego bądź systemów źródłowych. Jest to etap ekstrakcji danych. Następnie pobrane dane podlegają transformacji. Może ona polegać na oczyszczeniu, filtrowaniu bądź przekształceniu danych. W kolejnym kroku następuje załadowanie danych do systemu docelowego bądź systemów docelowych.
W przepływach ETL wszystkie etapy, czyli pobranie, transformacja oraz załadowanie danych, realizowane są poza systemem źródłowym oraz docelowym. Korzystamy z dodatkowego narzędzia.
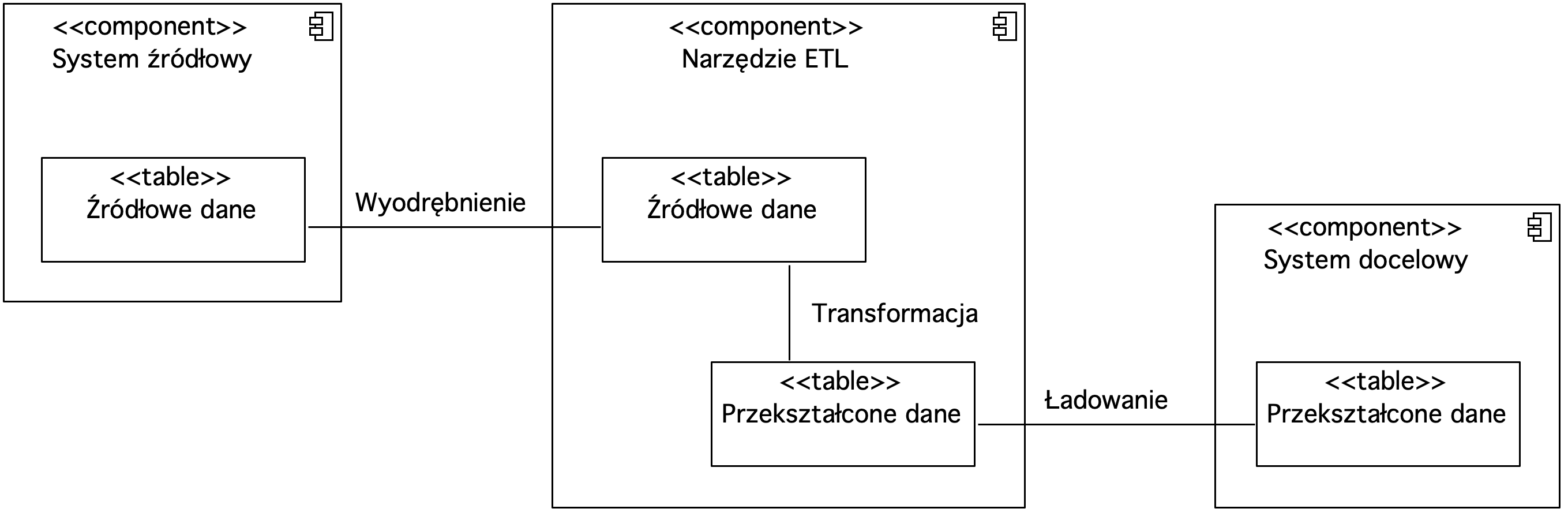
Rysunek 7. Diagram komponentów prezentujący narzędzie ETL
Na diagramie przesyłane dane zaprezentowane są jako komponent ze stereotypem tabeli. Narzędzie ETL pobiera dane z systemu źródłowego. Następnie dane źródłowe poddane są transformacji. Przekształcone dane ładowane są do systemu docelowego przez narzędzie ETL. W przepływie ETL kroki pobrania, transformacji oraz ładowania realizowane są za pośrednictwem narzędzia zewnętrznego w stosunku do systemu źródłowego oraz systemu docelowego.
Popularnymi narzędziami wykorzystywanymi w celu implementacji ETL/ELT są IBM DataStage (https://www.ibm.com/products/datastage), Apache NiFi (https://nifi.apache.org/), Apache Spark (https://spark.apache.org/) z Hadoop (https://hadoop.apache.org/) czy Amazon Glue (https://aws.amazon.com/glue/).
Przepływy ELT
ELT (ang. Extract, Load, Transform) – jest to proces, który polega na pobraniu, załadowaniu oraz przekształceniu danych. Kroki załadowania oraz przekształcenia danych występują w innej kolejności w porównaniu do procesu ETL. W pierwszym kroku następuje pobranie danych z systemu źródłowego bądź systemów źródłowych oraz następnie załadowanie do systemu docelowego. Kolejnym etapem jest transformacja danych, która może zostać zrealizowana przez systemu źródłowy.
Bardzo często transformacja w procesach ELT realizowana jest przez silnik bazy danych systemu docelowego, w związku z tym nie musimy korzystać z dodatkowego narzędzia.
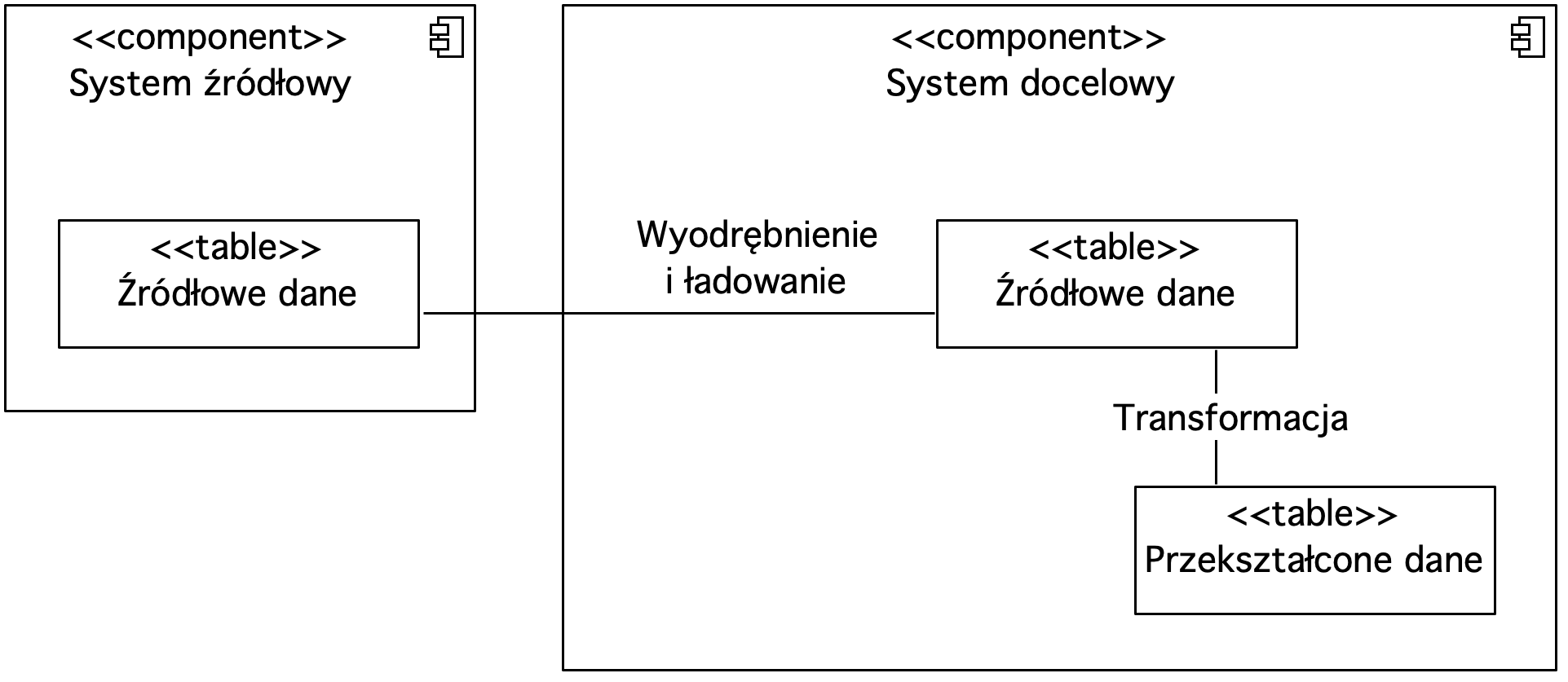
Rysunek 8. Diagram komponentów prezentujący narzędzie ELT
Na diagramie przesyłane dane zaprezentowane są jako komponent ze stereotypem tabeli. Dane źródłowe są wyodrębnione oraz ładowane do systemu docelowego. Następnie wykonywana jest transformacja danych. W przepływie ELT kroki wyodrębnienia, ładowania oraz transformacji mogą być realizowane przez system docelowy.
Popularnymi narzędziami wykorzystywanymi w celu implementacji ETL/ELT są IBM DataStage, Apache NiFi, Apache Spark z Hadoop czy Amazon Glue.
Szyna integracyjna
Szyna integracyjna (ang. Enterprise Service Bus) umożliwia integrację heterogenicznych systemów informatycznych za pomocą centralnej szyny integracji. ESB zapewnia łatwe dołączenie bądź odłączenie systemu informatycznego poprzez kanały i adaptery. Udostępnia usługi, które mogą być wykorzystywane przez różnych konsumentów. Zastosowanie kanonicznego modelu danych usprawnia zarządzanie modelem komunikatów. Szyna integracyjna eliminuje problem integracji punkt-punkt pomiędzy systemami informatycznymi. Może być wąskim gardłem.
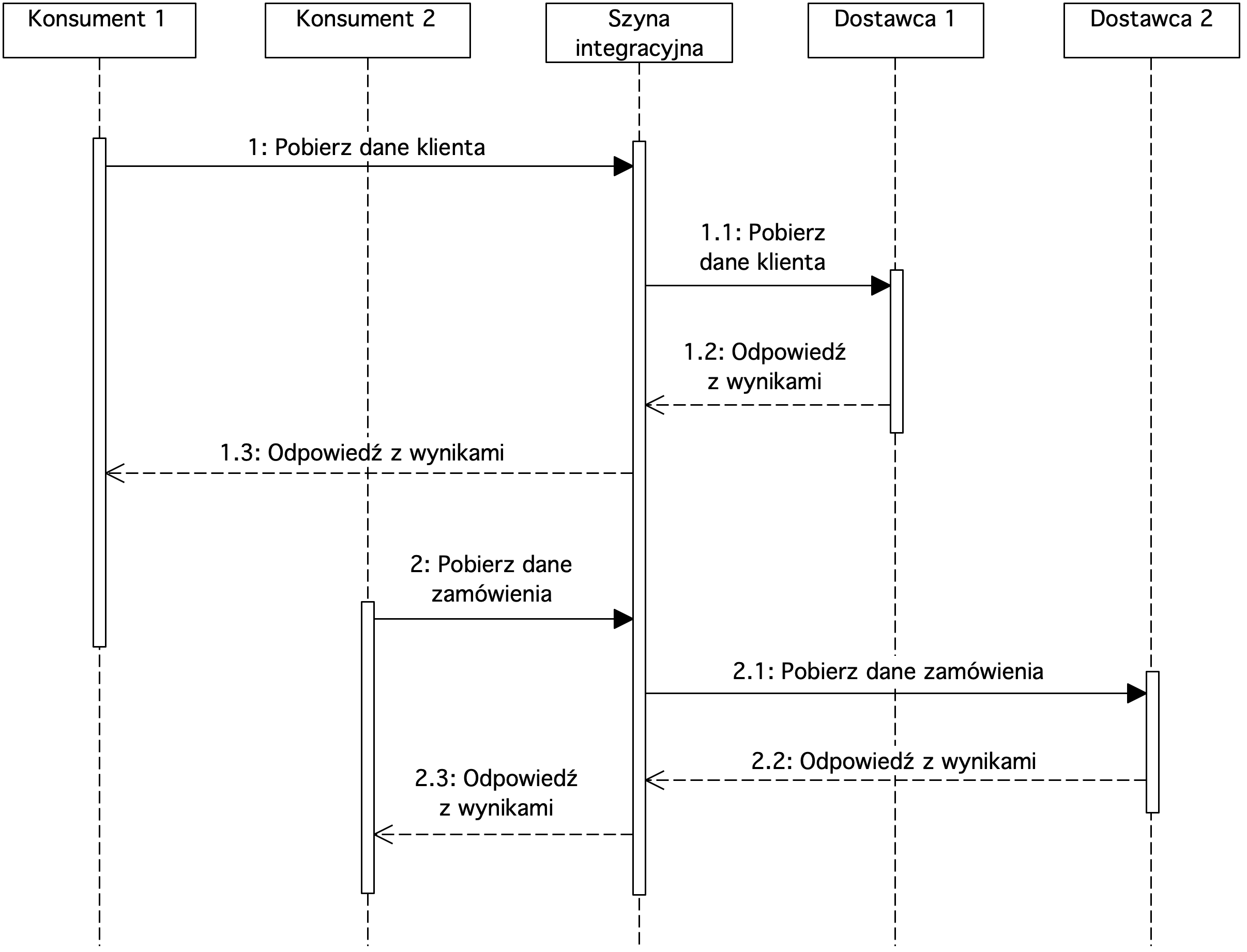
Rysunek 9. Diagram sekwencji prezentujący szynę integracyjną
Szyna integracyjna ESB udostępnia usługi konsumentom. W tym przypadku dostępne są usługi do pobrania danych klienta oraz pobrania danych zamówienia. Konsumenci nie muszą znać szczegółów działania usług ani systemów IT z których pobierane są dane.
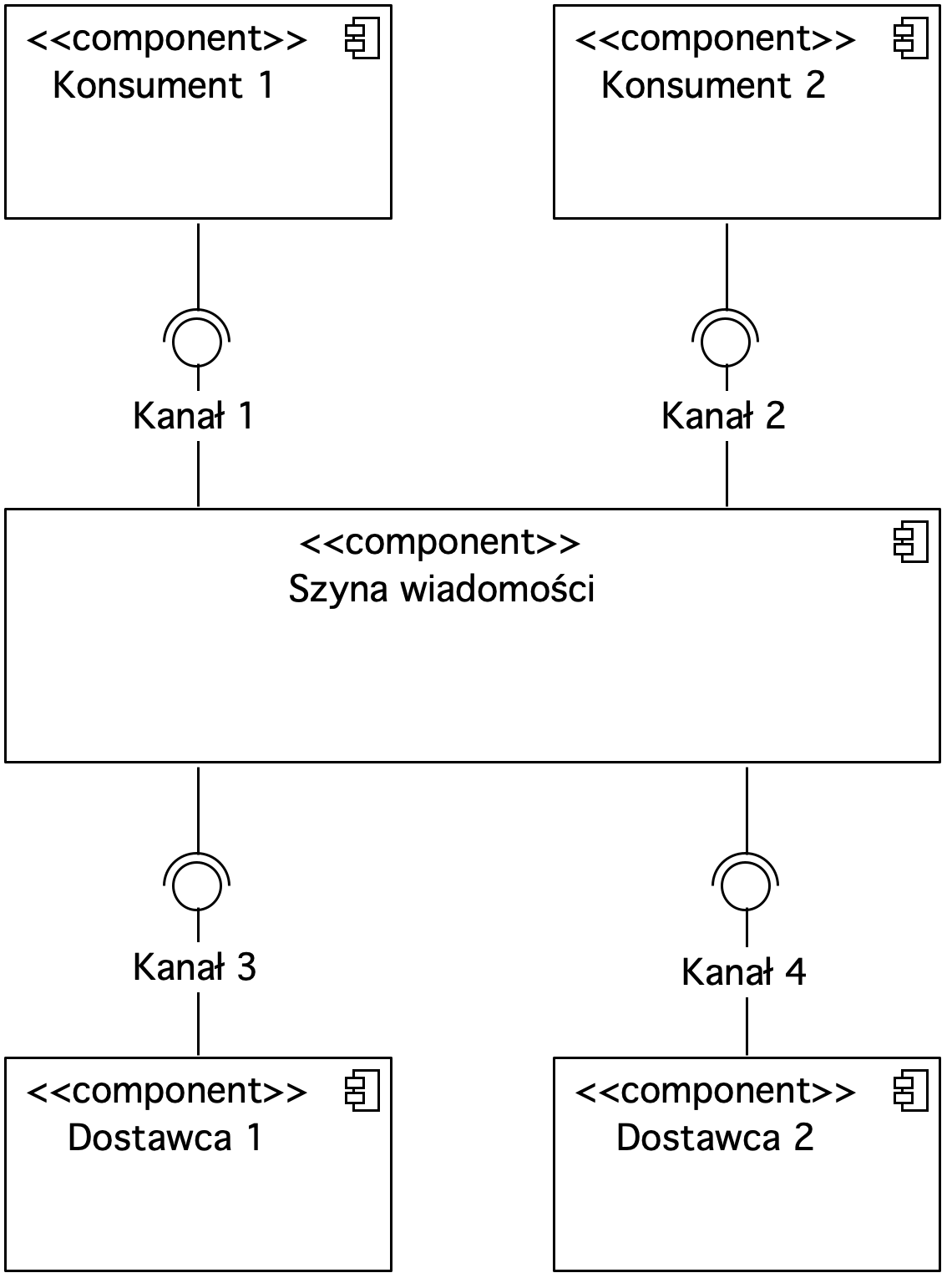
Rysunek 10. Diagram komponentów prezentujący szynę integracyjną
Szyna integracyjna ESB przykrywa również logikę usług. Konsument nie musi implementować złożonej logiki serwisu. Serwis udostępniony na ESB może być wykorzystany przez innych konsumentów. Wykorzystanie kanonicznego modelu danych umożliwia łatwe dołączanie oraz odłączanie systemów IT.
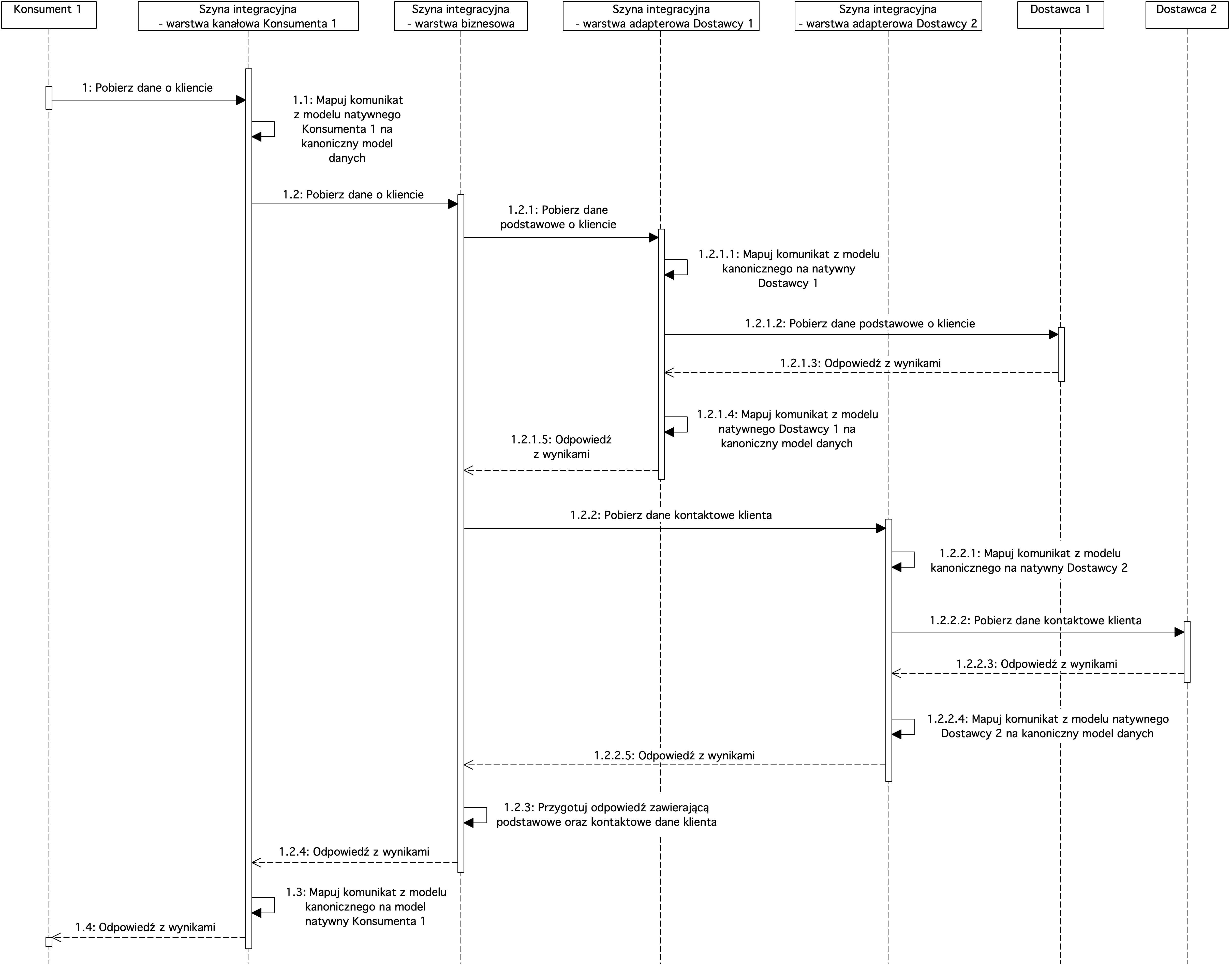
Rysunek 11. Diagram sekwencji prezentujący szczegóły usług szyny integracyjnej
Diagram zawiera przykładowy przepływ na szynie integracyjnej ESB. Konsument przekazuje żądanie pobrania danych o kliencie zgodnie ze swoim natywnym modelem danych. Konsument integruje się z warstwą kanałową szyny integracyjnej, gdzie następuje przekształcenie komunikatu z formatu natywnego Konsumenta 1 na kanoniczny model danych. Następnie komunikat przekazany jest do warstwy biznesowej pobrania danych o kliencie.
Usługi w warstwie biznesowej korzystają z kanonicznego modelu danych. Umożliwia to łatwą integrację usług warstwy biznesowej między sobą. Usługa biznesowa zawiera logikę pobrania danych podstawowych klienta z systemu Dostawcy 1 oraz danych kontaktowych klienta z systemu Dostawcy 2. W tym celu usługa biznesowa przekazuje żądanie pobrania podstawowych danych klienta do warstwy adapterowej systemu Dostawcy 1. W warstwie adapterowej Dostawcy 1 następuje przekształcenie komunikatu z modelu kanonicznego na model natywny Dostawcy 1. Następnie warstwa adapterowa wysyła żądanie do Dostawcy 1. Po otrzymaniu odpowiedzi w warstwie adapterowej Dostawcy 1 następuje przekształcenie komunikatu z postaci natywnej Dostawcy 1 na kanoniczny model danych oraz przekazanie do warstwy biznesowej.
W kolejnym kroku w warstwie biznesowej następuje pobranie danych kontaktowych klienta. W tym celu następuje przekazanie żądania do warstwy adapterowej systemu Dostawcy 2. W warstwie adapterowej wykonywane jest przekształcenie komunikatu z postaci kanonicznej na natywną dla systemu Dostawcy 2 oraz wywołanie systemu Dostawcy 2. Po otrzymaniu wyników w warstwie adapterowej następuje przekształcenie komunikatu z postaci natywnej Dostawcy 2 na postać kanoniczną oraz przekazanie wyników do warstwy biznesowej.
Kolejnym krokiem jest połączenie danych o kliencie pobranych z systemu Dostawcy 1 oraz danych kontaktowych klienta pobranych z systemu Dostawcy 2. Po przygotowaniu odpowiedzi jest ona przekazywana do warstwy kanałowej Konsumenta 1, gdzie następuje mapowanie komunikatu z postaci kanonicznej na natywną Konsumenta 1 oraz zwrócenie wyników do Konsumenta 1.
Popularnymi implementacjami ESB są webMethods Integration Server (https://www.softwareag.com/en_corporate/platform/integration-apis/webmethods-integration.html) (webMethods ESB) bądź Mule ESB.
Dziękuję Ci za przeczytanie artykułu. Gdybyś chciał/chciała podzielić się ze mną swoim komentarzem napisz do mnie na marcin@marcinziemek.com
Jeśli chcesz rozwinąć swoją wiedzę z zakresu projektowania integracji systemów IT, sprawdź moją książkę dostępną pod adresem: https://integracja.marcinziemek.com