
Projektowanie integracji systemów IT
Opublikował Marcin Ziemek w dniu 13-11-2021Czy zastanawiałeś się kiedyś, w jaki sposób projektować integrację systemów IT oraz kiedy, jakie rozwiązanie/technologię integracji wybrać? Chciałbyś dowiedzieć się jak wygląda proces projektowania integracji systemów IT? Z tego tekstu dowiesz się na czym polega projektowanie integracji systemów IT oraz kiedy, jakie rozwiązanie czy technologię integracji wybrać.
Artykuł jest transkrypcją fragmentu mojej prezentacji z konferencji Warszawskie Dni Informatyki z roku 2021
Jeśli chcesz rozwinąć swoją wiedzę z zakresu projektowania integracji systemów IT, sprawdź też moją książkę dostępną pod adresem: https://integracja.marcinziemek.com
Jak projektować integrację systemów informatycznych?
Podczas prezentacji odpowiemy na pytanie w jaki sposób projektować integrację systemów informatycznych, skupimy się na kwestiach związanych z wyborem rozwiązania integracyjnego oraz technologii integracyjnych.

Rysunek 1. Jak projektować integrację systemów informatycznych?
Od czego zacząć projektowanie integracji? Czy od wyboru stylu architektonicznego typu REST? Czy od rozwiązania integracyjnego typu Kafka? A może od formatu danych wykorzystanego w integracji jak JSON czy XML? Być może od języka programowania jak Java?

Rysunek 2. Integracja – od czego zacząć?
Odpowiedź brzmi, że od żadnego z wymienionych wcześniej punktów. Za chwilę omówimy wspólnie jakie są kroki procesu projektowania integracji, na co należy zwrócić uwagę zanim przejdziemy do wyboru konkretnego rozwiązania, technologii czy formatu danych.
Rozpocznijmy jednak od definicji integracji.
Definicja integracji
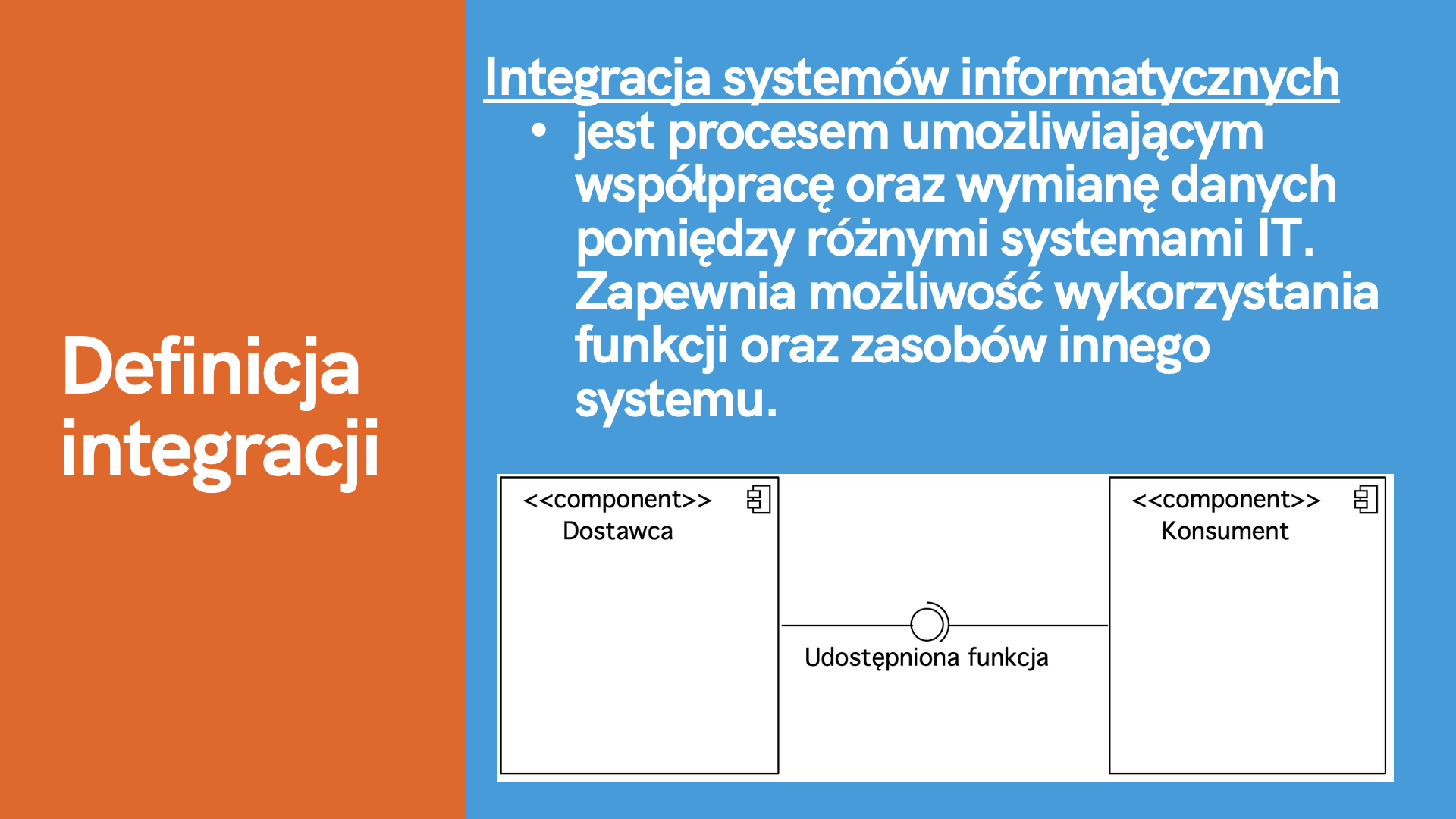
Rysunek 3. Definicja integracji
Integracja systemów informatycznych jest to proces, który zapewnia współpracę oraz wymianę danych pomiędzy różnymi systemami IT. Umożliwia wykorzystanie funkcji oraz zasobów jednego systemu przez inny.
W praktyce oznacza to, iż jeśli nasz system informatyczny nie posiada funkcji generowania faktur wówczas możemy wykorzystać inny system, który taką funkcję posiada. Nie jest konieczna rozbudowa systemu, gdy istnieje możliwość integracji z innymi systemami w celu wykorzystania ich funkcji lub zasobów.
Dostawca udostępnia funkcję. Następnie jest ona wykorzystywana przez Konsumenta. Podczas projektowania integracji musimy pamiętać, aby udostępniać tylko funkcję oraz zasoby, które są niezbędne przez inny system.
Przejdźmy do zalet oraz wad integracji systemów informatycznych.
Zalety oraz wady integracji systemów informatycznych

Rysunek 4. Zalety oraz wady integracji systemów informatycznych
Integracja systemów informatycznych umożliwia korzystanie z funkcji oraz zasobów innego systemu informatycznego. Nie jest konieczna rozbudowa jednego systemu o funkcje, które realizuje inny system informatyczny. Integracja systemów informatycznych może przyczynić się do zwiększenia wydajności i jakości pracy przedsiębiorstwa oraz pracowników. Na przykład wprowadzenie integracji automatycznej przekazującej dane pomiędzy systemami informatycznymi wykorzystywanymi przez pracowników zapewni ich spójność. Dane klienta jak adres czy numer telefonu będą spójne w różnych systemach. Zmiana danych kontaktowych w jednym systemie spowoduje zaktualizowanie tych danych w innych systemach. Wprowadzenie integracji automatycznej umożliwia wyeliminowanie błędów związanych z ręcznym wprowadzaniem tych samych danych do kilku systemów. Musimy jednak pamiętać, że zalety oraz wady integracji należy analizować w kontekście konkretnego przypadku użycia.
Omówmy teraz od czego zacząć projektowanie integracji oraz wybór rozwiązania integracyjnego.
Od czego zacząć?
Projektowanie integracji najlepiej przeprowadzić zgodnie z procesem. Omówmy pokrótce ten proces.

Rysunek 5. Proces projektowania architektury integracji (1/3)
Powinniśmy rozpocząć od analizy problemu biznesowego lub potrzeby biznesowej.
W kolejnym kroku musimy zapoznać się z wymaganiami funkcjonalnymi oraz niefunkcjonalnymi. Wymagania mogą ograniczać możliwe rozwiązania integracyjne na przykład wymuszając zastosowanie konkretnego protokołu komunikacji, metody autoryzacji czy bezpieczeństwa.
Następnie konieczne jest przeanalizowanie procesów biznesowych. Istotne jest, aby określić czy proces oraz jego kroki realizowane są w czasie rzeczywistym czy nie. Konieczne jest również zrozumienie zmienności pobieranych oraz przekazywanych danych. Jeśli dane modyfikowane są u źródła raz w miesiącu wówczas nie ma potrzeby ich przekazywania w mniejszej częstotliwości. Należy również zrozumieć, które kroki procesu biznesowego realizowane są automatycznie, semi-automatycznie bądź manualnie. Na tym etapie istotne jest również, aby zrozumieć kto jest aktorem inicjującym proces.
W kolejnym kroku następuje analiza przypadków użycia. Musimy zwrócić uwagę na interakcję aktorów.

Rysunek 6. Proces projektowania architektury integracji (2/3)
Następnie konieczna jest analiza wizji architektonicznej. Kluczowe jest zrozumienie, które interfejsy będą występowały w architekturze docelowej, a które będą modyfikowane lub planowane jest ich usunięcie w kolejnych fazach rozwoju rozwiązania.
W kolejnym kroku analizujemy architekturę biznesową. Musimy określić, czy proces i jego kroki realizowane są w czasie rzeczywistym czy nie. Konieczne jest również określenie zmienności pobieranych i przekazywanych danych. Niektóre interfejsy muszą być wykorzystywane raz na dzień lub raz w tygodniu. Inne mogą być wywoływane w czasie rzeczywistym po żądaniu użytkownika i konieczne jest natychmiastowego przekazanie wyniku.
Następnie niezbędne jest przeanalizowanie architektury danych w ramach, której przygotowany został biznesowy model danych dla rozwiązania. Zostanie on również wykorzystany w celu przygotowania modelu danych komunikacji.
W kolejnym kroku należy przeanalizować architekturę aplikacji, gdzie szczególną uwagę musimy zwrócić na interfejsy udostępniane oraz wykorzystywane przez komponenty. Podczas definiowania integracji pomiędzy aplikacjami (komponentami) przygotowywane są przypadki integracyjne, struktury danych wejściowych, wyjściowych w ramach przypadków oraz scenariusze integracyjne. Szczegóły integracyjne dotyczące typu komunikacji (np. synchroniczna), protokołu komunikacji (np. HTTP), kody błędów oraz bezpieczeństwa zostaną przygotowane w ramach architektury integracji.

Rysunek 7. Proces projektowania architektury integracji (3/3)
Po analizie architektury biznesowej, danych oraz aplikacji posiadamy wiedzę na temat interfejsów koniecznych do zdefiniowania.
Podczas prac nad architekturą biznesową poznaliśmy, czy integracja musi być realizowana w czasie rzeczywistym czy nie, przeanalizowaliśmy aktorów i ogólny zakres danych przekazywany w krokach procesów. Na etapie prac nad architekturą danych poznaliśmy logiczny model danych wykorzystywany w rozwiązaniu. Podczas pracy nad architekturą aplikacji przeanalizowaliśmy przypadki integracyjne, struktury danych wejściowych, wyjściowych w ramach przypadku oraz scenariusze integracyjne.
W kolejnym kroku podczas pracy nad architekturą integracji należy skupić się na zaprojektowaniu interfejsów w tym ustaleniu typu komunikacji (np. synchroniczna), protokołu komunikacji (np. HTTP), formatu przekazywanych danych (np. JSON), modelu danych komunikacji, obsługi błędów oraz bezpieczeństwa. Na tym etapie uszczegółowimy specyfikację interfejsów.
Po zakończeniu projektowania integracji należy wykonać analizę architektury technicznej, infrastruktury, bezpieczeństwa oraz wdrożenia. Warto również przeanalizować wynik weryfikacji architektury.

Rysunek 8. Proces projektowania architektury integracji (1/2)
W celu zaprojektowania interfejsów konieczne są:
- Zdefiniowanie typu przetwarzania danych (online, offline),
- Zdefiniowanie trybu integracji (automatyczna, semi-automatyczna, manualna),
- Zdefiniowanie typu integracji (pull, push),
- Zdefiniowanie protokołu integracyjnego,

Rysunek 9. Proces projektowania architektury integracji (2/2)
- Zdefiniowanie formatu danych,
- Zdefiniowanie modelu danych komunikacji w tym określenie technicznej specyfikacji wejścia/wyjścia,
- Zdefiniowanie obsługi błędów,
- Zdefiniowanie wydajności oraz bezpieczeństwa,
- Zdefiniowanie technologii integracji,
- Zdefiniowanie scenariuszy integracyjnych.
Typ przetwarzania danych (online, offline)
Jednym z kluczowym kryteriów podczas projektowania integracji systemów informatycznych jest zrozumienie czy proces biznesowy oraz jego kroki muszą być przetwarzane w czasie rzeczywistym czy nie (tak zwane przetwarzanie online lub offline).
Omówmy teraz czym jest integracja online a czym offline.

Rysunek 10. Integracja online oraz offline
Integracje online wykorzystujemy w celu przekazywania danych w czasie rzeczywistym. Z związku z tym zakres przekazywanych danych nie może być bardzo duży. Musimy zwrócić uwagę również na całkowity czas odpowiedzi udostępnionej funkcji, który zawiera wysłanie żądania przez Konsumenta, następnie przygotowanie danych oraz przekazanie odpowiedzi przez Dostawcę. Operacja przygotowania danych odpowiedzi nie może być bardzo czasochłonna. Przykładowo operacja wyszukania koszuli zainicjowana przez klienta korzystający z platformy zakupowej nie może trwać godziny. Wyniki powinny być dostępne w ciągu milisekund. W dalszej części rozdziału omówimy mechanizmy, które możemy zastosować, gdy operacja przygotowania danych zajmuje dużo czasu - jak buforowanie bądź stronicowanie. Integracje online są trudniejsze do zaprojektowania, implementacji, utrzymania oraz bardziej kosztowne.
Z kolei integracje offline są bardzo dobrym rozwiązaniem w przypadku procesów, które nie muszą być przetwarzane w czasie rzeczywistym. Przykładowo procesy związane z raportowaniem, wyznaczaniem rekomendacji, scoringu klienta, ratingu są procesami uruchamianymi na przykład co jeden dzień, tydzień bądź miesiąc. W związku z tym wymagane dane mogą zostać pobrane w trybie batchowym czyli offline co dzień, tydzień bądź miesiąc. Gdy jest to możliwe wówczas należy rozważyć wykorzystanie integracji offline, gdyż jest przeważnie łatwiejsza do zaprojektowania, implementacji oraz utrzymania.
Ustalenie typu przetwarzania danych jest bardzo ważne, gdyż wpływa na wszystkie kolejne szczegóły integracji.
Tryb integracji (automatyczna, semi-automatyczna, manualna)
Kolejnym kryterium jest określenie trybu integracji – automatyczna, semi-automatyczna lub manualna. Integracja automatyczna polega na tym, że nie jest konieczna ingerencja ludzka w przekazywanie oraz odbieranie danych pomiędzy systemami (dostawcą oraz konsumentem).
W celu lepszego zrozumienia integracji automatycznej omówimy ją na przykładzie zaprezentowanym na diagramie.
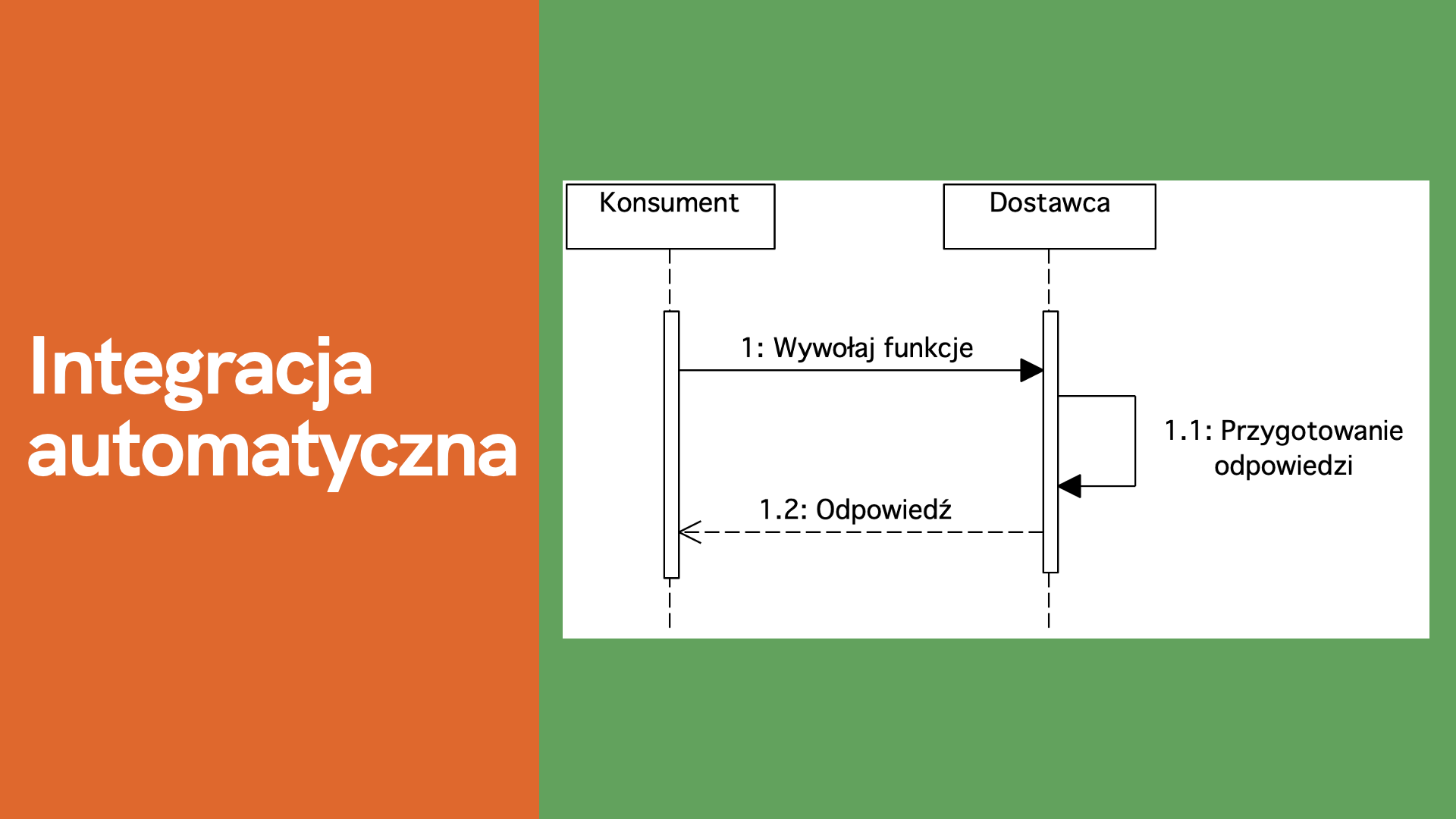
Rysunek 11. Integracja automatyczna
Konsument inicjuje żądanie wywołania funkcji. Jest ona udostępniona przez Dostawcę. Po otrzymaniu żądania następuje przygotowanie odpowiedzi przez Dostawcę. Następnie przekazana jest odpowiedź do Konsumenta. Integracja odbywa się automatycznie bez ingerencji ludzkiej.
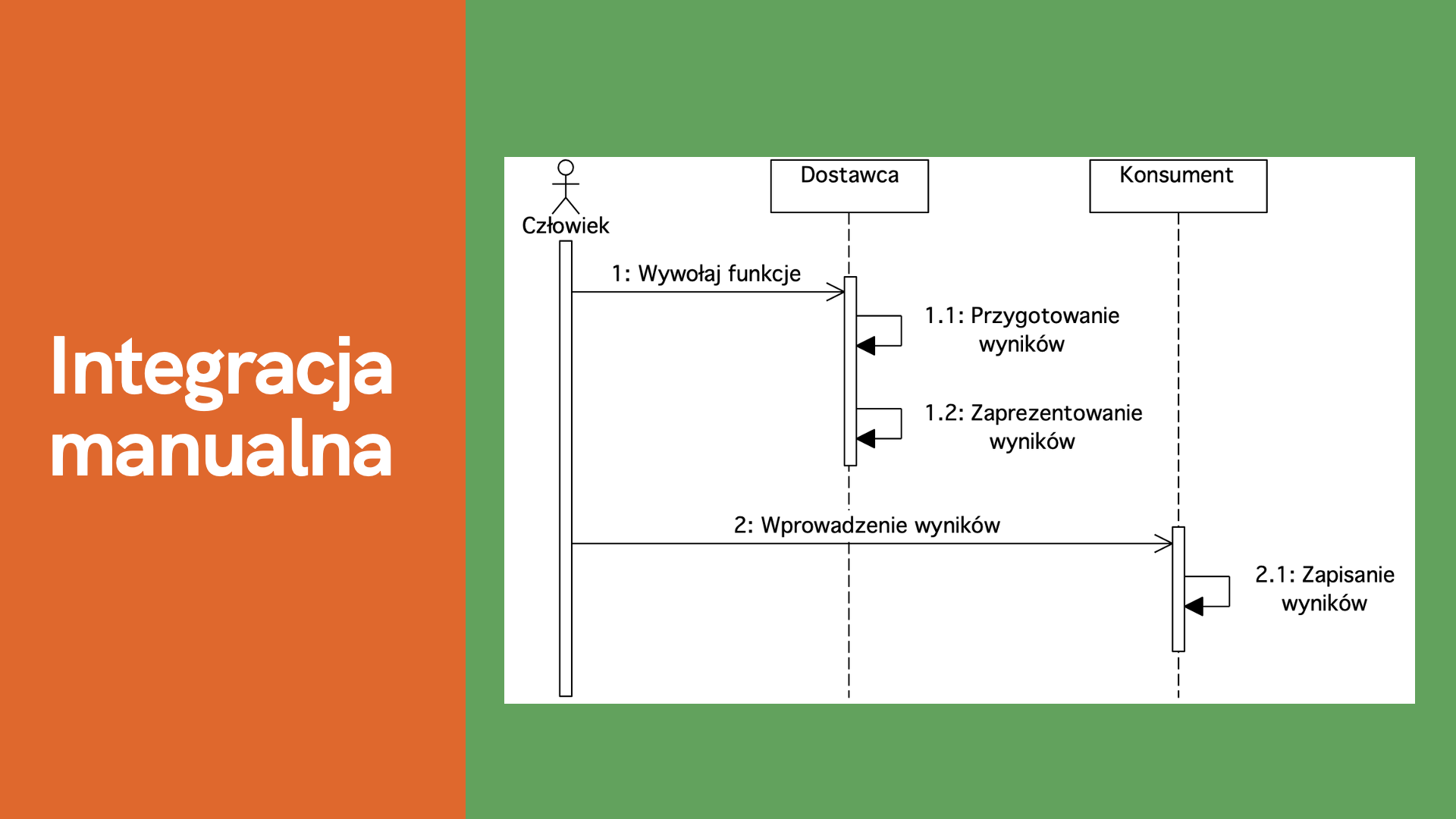
Rysunek 12. Integracja manualna
Podczas integracji manualnej występuje ingerencja człowieka. W naszym przykładzie człowiek ręcznie wywołuje funkcję u Dostawcy. Może być to funkcja wyszukania ubrań, wyznaczenia rekomendacji czy wygenerowania raportu. Następnie Dostawca odpowiada za przygotowanie wyników oraz zaprezentowanie użytkownikowi. W kolejnym kroku człowiek wprowadza wyniki do Konsumenta, gdzie są zapisywane. W integracji manualnej człowiek odpowiada za inicjowanie funkcji u Dostawcy oraz przekazanie danych do Konsumenta.
Integracje manualne budujemy, gdy interfejs jest tymczasowy, będzie rzadko wykorzystywany bądź wprowadzenie interfejsu automatycznego jest zbyt kosztowe.
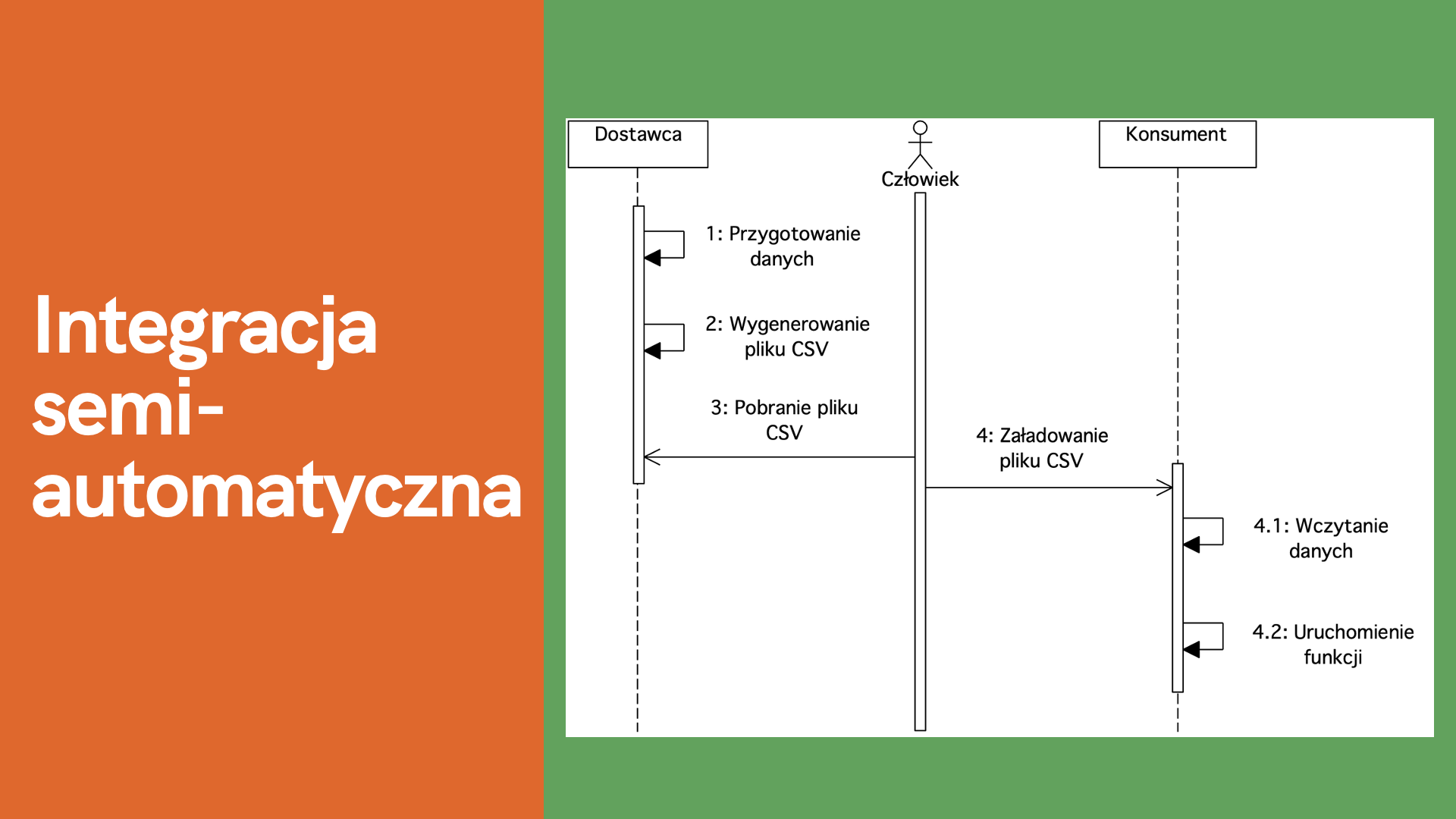
Rysunek 13. Integracja semi-automatyczna
Integracja semi-automatyczna oznacza, że wymagana jest ingerencja ludzka, ale w ograniczonym zakresie. W powyższym przykładzie Dostawca przygotowuje dane oraz generuje plik CSV. Następnie człowiek pobiera wygenerowany plik oraz wczytuje u Konsumenta. Po załadowaniu pliku u Konsumenta następuje wczytanie danych oraz uruchomienie funkcji.
Ingerencja ludzka w przypadku integracji semi-automatycznej jest bardzo ograniczona. W tym przypadku rola człowieka ogranicza się do przekazania pliku pomiędzy Dostawcą oraz Konsumentem. Człowiek nie wprowadza żadnych danych ręcznie, nie wykonuje operacji wyszukania czy wyboru danych do przesłania. Ingerencja ludzka ogranicza się tylko do czynności, która nie ma wpływu na generowanie danych po stronie Dostawcy czy wczytania oraz uruchomienia funkcji po stronie Konsumenta.
Typ integracji (synchroniczna, asynchroniczna)
Następnym kryterium jest określenie typu integracji – synchroniczna (pull) lub asynchroniczna (push).
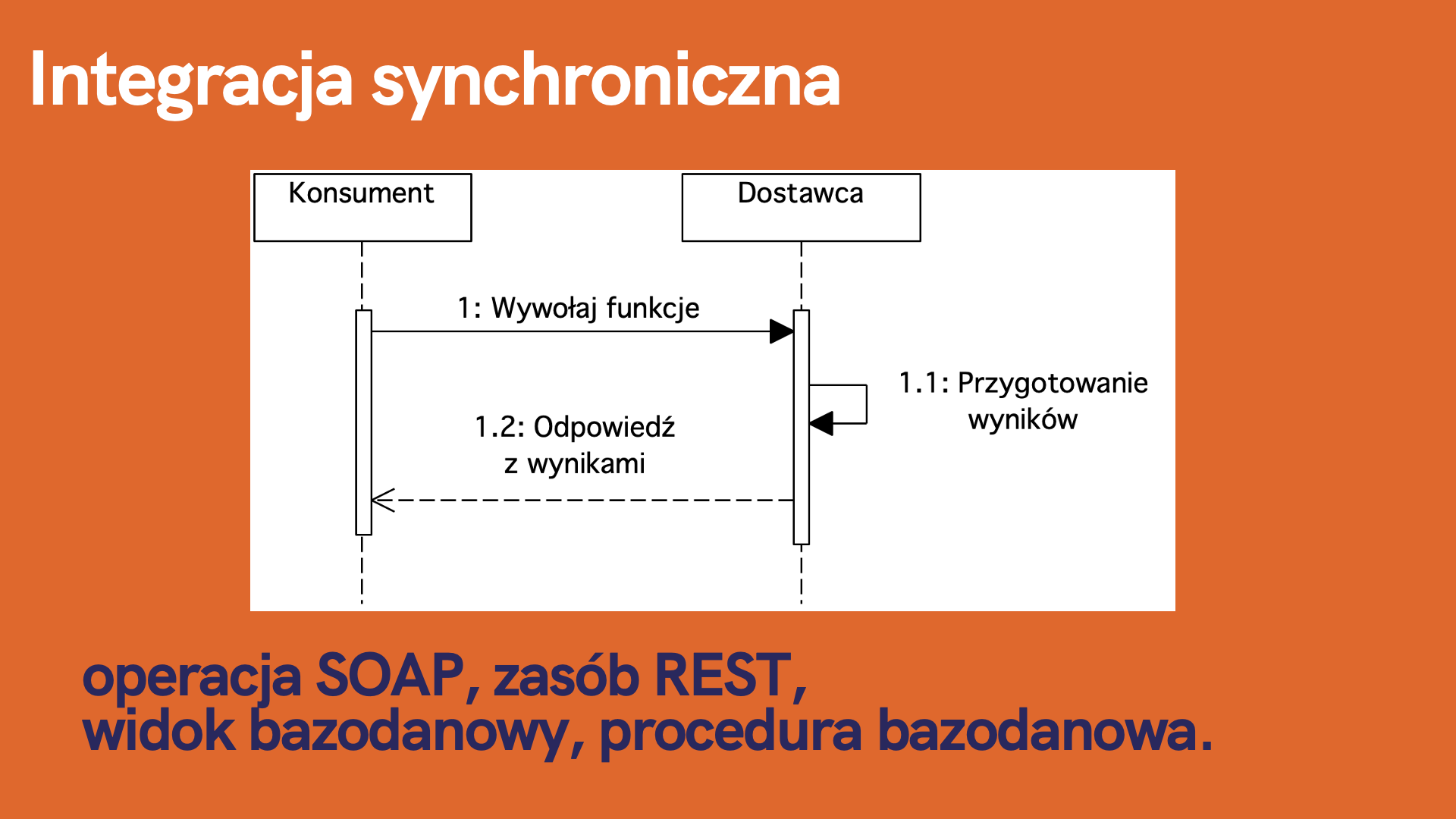
Rysunek 14. Integracja synchroniczna
Integracja synchroniczna oznacza, że Konsument po zainicjowaniu żądania oczekuje na odpowiedź z wynikami od Dostawcy. Jest to integracja jeden do jednego (1:1) pomiędzy Konsumentem oraz Dostawcą. Najpopularniejszymi rozwiązaniami tego typu są zasoby REST, operacje webservices SOAP czy pobranie danych z bazy danych po JDBC/ODBC.
W integracji synchronicznej Konsument wywołuje funkcję u Dostawcy. Następnie otrzymuje odpowiedź z wynikami. Aktorem inicjującym wywołanie funkcji jest Konsument. Wywołanie funkcji po stronie Dostawcy odbywa się poprzez API, którym może być operacja SOAP, zasób REST, widok czy procedura bazodanowa. Integrację typu pull wykorzystujemy, gdy to konsument chce mieć kontrolę, kiedy wywołać funkcję. Przykładowo operacja pobrania danych Klienta czy wyszukanie posiłku w restauracjach są operacjami, gdzie powinniśmy zastosować integracje typu pull.
W przypadku integracji typu pull bardzo często spotykamy się z rozwiązaniami:
- udostępnienie operacji SOAP,
- udostępnienie zasobu REST,
- udostępnienie widoku bazodanowego,
- udostępnienie procedury bazodanowej.
Widoki bazodanowe wykorzystywane są do operacji przeglądania, wyszukania natomiast procedury do zapisu czy aktualizacji.
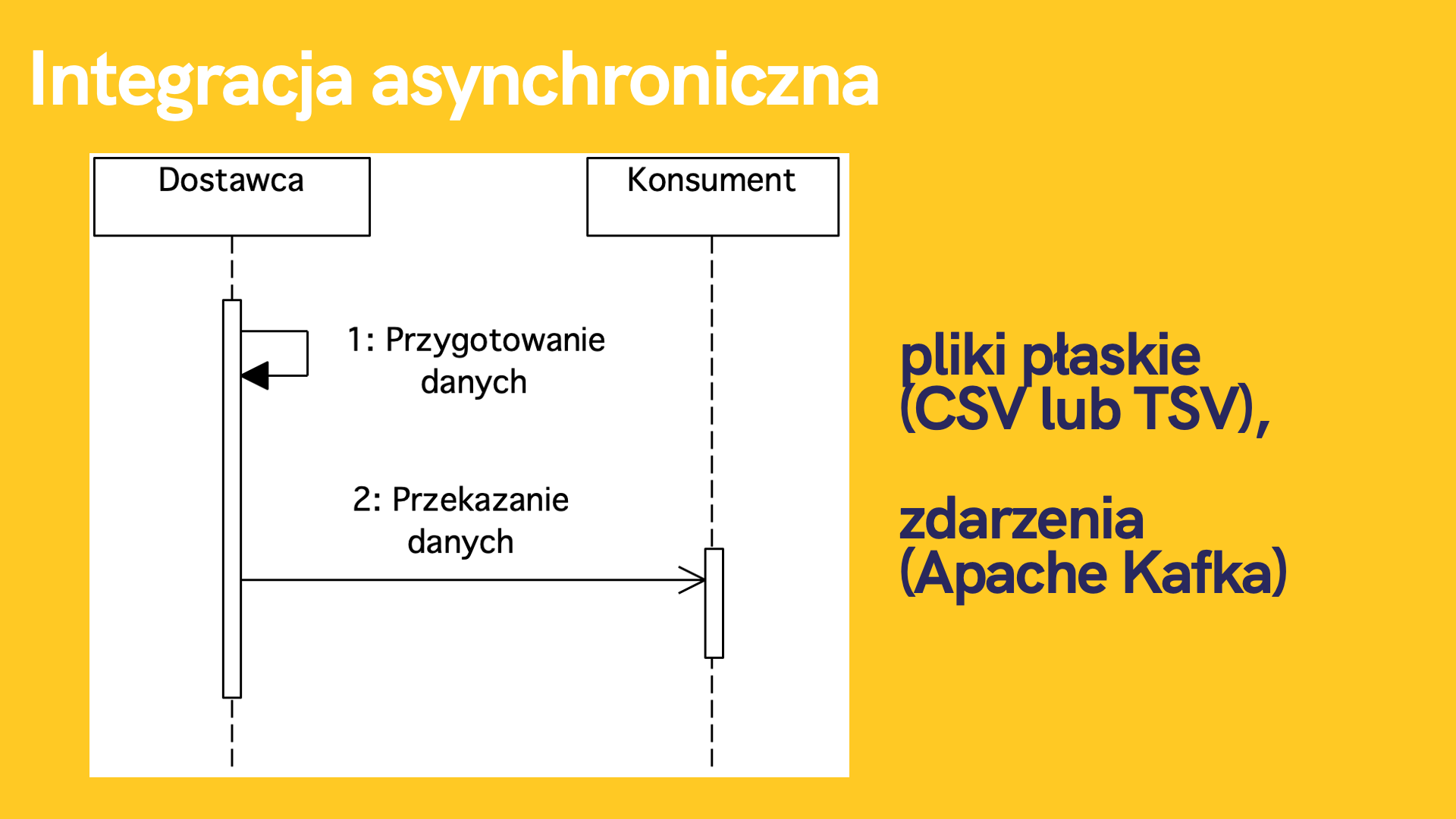
Rysunek 15. Integracja asynchroniczna
W integracji asynchronicznej Dostawca przygotowuje dane oraz przekazuje do Konsumenta bądź Konsumentów. Aktorem inicjującym jest Dostawca, który może przekazać dane na przykład, gdy ulegną zmianie. Jest to wywołanie jeden do wielu (1:N) pomiędzy Dostawcą oraz Konsumentami. Przykładem jest operacja przekazania notyfikacji o statusie zamówienia. W chwili, gdy status zamówienia ulegnie zmianie wówczas przekazywana jest notyfikacja o aktualnym statusie do wszystkich Konsumentów.
W przypadku integracji typu push bardzo często spotykamy się z rozwiązaniami:
- przekazanie danych poprzez pliki płaskie (CSV lub TSV),
- przekazanie danych poprzez Apache Kafka.
Pliki płaskie wykorzystywane są do integracji wsadowej (offline), natomiast Apache Kafka do integracji w czasie rzeczywistym (online).
Protokół integracyjny
W kolejnym kroku niezbędne jest określenie protokołu komunikacji, który wykorzystamy w naszym rozwiązaniu.
Protokół komunikacyjny jest zestawem reguł wykonywanych przez komputery w sieci, aby móc się ze sobą komunikować. Reguły określają rodzaj danych możliwy do przesłania, polecenia, które są możliwe do wysłania i odbioru oraz sposoby potwierdzania.

Rysunek 16. Protokół integracyjny
Integracja online może zostać zrealizowana za pośrednictwem protokołu HTTP. Integracja offline wymiany danych poprzez pliki płaskie z wykorzystaniem FTP.
Innymi popularnymi protokołami są SMTP, IMAP/POP3, SOAP, RPC czy JDBC/ODBC.
Format danych
Następnie musimy określić format danych wykorzystany w integracji.
Format danych jest sposobem zapisu danych.

Rysunek 17. Format danych
Popularnymi formatami w integracjach online są JSON, XML bądź Avro.
W integracjach offline opartych na plikach popularnym formatem jest CSV/TSV.
Inne kryteria
Następnie należy zwrócić uwagę na inne kryteria.

Rysunek 18. Inne kryteria
Musimy wziąć pod uwagę na kwestie związane z wydajnością, czasem odpowiedzi oraz bezpieczeństwem. Polityka organizacji może wymuszać na nas zastosowanie bezpiecznych protokołów HTTPS, SFTP czy certyfikatów X.509 z kluczem RSA. Należy zastanowić się czy konieczne jest dodanie buforowania czy stronicowania.
Technologie oraz rozwiązania integracyjne
Po ustaleniu typu przetwarzania (online, offline), trybu integracji (automatyczna, semi-automatyczna, manualna), typu integracji (pull, push), protokołu integracyjnego, formatu danych, wydajności, bezpieczeństwa możemy przystąpić do wyboru technologii. Musimy pamiętać również, aby przy wyborze uwzględnić zasady architektury integracji dostępne w naszej organizacji. Jeśli zasady definiują, aby wszystkie interfejsy typu online, pull były budowane z wykorzystaniem SOAP oraz HTTPS wówczas musimy je uwzględnić.

Rysunek 19. Najpopularniejsze rozwiązania/technologie integracyjne
Najpopularniejszymi rozwiązaniami/technologiami integracyjnymi są:
- Szyny integracyjne (np. webMethods, Tibco, IBM),
- Systemy kolejek MQ,
- Tematy Kafka,
- Zasoby REST,
- Operacje SOAP,
- Przepływy ETL/ELT (np. DataStage, Hadoop ze Spark),
- Przesyłanie plików płaskich CSV/TSV.
W celu implementacji integracji synchronicznej możemy wykorzystać zasoby REST czy operacje SOAP. Do implementacji integracji asynchronicznej możemy skorzystać z systemu kolejek MQ. W celu implementacji interfejsu online powinniśmy wykorzystać zasoby REST, operacje SOAP, systemu kolejek MQ bądź tematów Kafka. Do implementacji integracji offline możemy skorzystać z przepływów ETL.
Wzorce integracyjne
Podczas projektowania integracji warto rozważyć wykorzystanie wzorców integracyjnych.
Wzorce integracyjne (ang. integration patterns) są sprawdzonymi sposobami rozwiązania określonego problemu integracyjnego.
Najpopularniejszymi wzorcami integracyjnymi są:
- Wzorzec integracji synchronicznej żądanie oraz odpowiedź (ang. request-response),
- Wzorzec integracji asynchronicznej żądanie oraz zwrotka (ang. request-reply),
- Wzorzec integracji identyfikator korelacji (ang. correlation identifier),
- Wzorzec integracji punkt-punkt (ang. point-to-point),
- Wzorzec integracji publikuj-subskrybuj (ang. publish-subscribe),
- Wzorzec integracji kanały i procesory (ang. pipes and filters),
- Wzorzec integracji router sterowany treścią wiadomości (ang. content based router),
- Wzorzec integracji wzbogacacz treści (ang. content enricher),
- Wzorzec integracji rozdzielacz (ang. splitter),
- Wzorzec integracji agregator (ang. aggregator),
- Wzorzec integracji Broker wiadomości (ang. Message Broker),
- Wzorzec integracji Szyna wiadomości (ang. Message Bus),
- Wzorzec integracji kanoniczny model danych (ang. canonical data model).
Ze szczegółami wymienionymi wyżej wzorców integracyjnych możesz zapoznać się w moim artykule - Przegląd wzorców integracyjnych
Zasady architektury integracji
Zasady architektury integracji zawierają wytyczne, którymi powinniśmy się kierować podczas projektowania integracji. W organizacjach określane są zasady, które powinny być uwzględniane podczas projektowania interfejsów. Zasady mogą dotyczyć standardów bezpieczeństwa jakie należy zastosować na przykład poprzez wykorzystanie protokołów zabezpieczonych SSH, HTTPS, SFTP itp., czy mechanizmów uwierzytelniania (wykorzystanie certyfikatów X.509). Mogą zawierać wymogi związane z nazewnictwem interfejsów integracyjnych czy wersji protokołu integracyjnego na przykład SOAP 1.2.
Gdybyś chciał podzielić się ze mną swoim komentarzem napisz do mnie na marcin@marcinziemek.com
Jeśli chcesz rozwinąć swoją wiedzę z zakresu projektowania integracji systemów IT, sprawdź też moją książkę dostępną pod adresem: https://integracja.marcinziemek.com